I’ve talked a lot about the LongMemEval dataset on my blog. If you’re not deep in the agent memory space, you’ve probably never heard of it. It’s a poster paper from ICLR 2025 that sets the new standard for what we expect from an agent’s memory. We’ve come a long way since early milestones like Meta’s Beyond Goldfish Memory paper and MemGPT, but that’s a story for another day.
Long story short, LongMemEval is the new gold standard for benchmarking conversational agent memory. I thought Zep/Graphiti was the clear leader, until I saw a comment on my previous post, The AI Memory Challenge, Part 1, from Marc, a Principal AI Research Scientist at Emergence AI. He invited me to check out their blog post, SOTA on LongMemEval with RAG, where they, well, beat Zep by a mile. 🤯
How They Did It
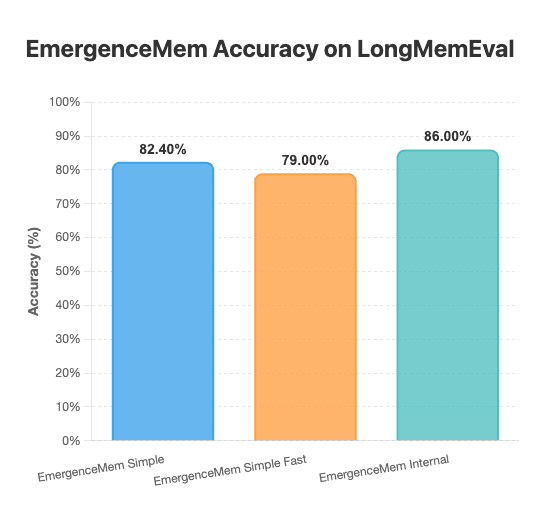
In their post, Emergence AI details three approaches that have set new records:
- EmergenceMem Simple — 82.40%
- EmergenceMem Simple Fast — 79.00%
- EmergenceMem Internal — 86.00%
Here’s a breakdown of the two methods they discuss publicly:
The EmergenceMem Simple approach is clever. Instead of retrieving individual conversational turns, it retrieves entire conversations. A session’s relevance score is based on how many of its turns appear in the top search results after reranking. For example, if the highest-ranked turns are mostly from Session 37, the entire Session 37 is pulled into context for the LLM.
The EmergenceMem Simple Fast approach uses two LLM calls:
- First, it performs a simple search to retrieve relevant turns from the conversation.
- Then, it combines the question and the retrieved turns into a prompt and makes an LLM call to extract key events and facts based on the question.
- The extracted summary is then used by the final LLM to generate the answer.
They offer more insight into their Internal version in another great post, State of the Art Results in Agentic Memory, which is a must-read if you’re interested in this topic.
In this post, I want to focus on EmergenceMem Simple Fast, because they’ve kindly [open-sourced it], allowing anyone to run and verify their results.
Can It Run on a Budget? Testing with GPT-4o Mini
Emergence AI’s published results use powerful models like GPT-4o, which makes sense for their enterprise focus. My work, however, is geared toward building consumer apps, where cost is a critical factor.
As I’ve written before in SLMs as the New Memory Core, the AI app ecosystem is held back by two main issues: an incomplete AI Tool Layer and prohibitively expensive tokens. The high cost of foundation models creates what I call the LLM-margin squeeze, making it incredibly difficult for developers to build sustainable applications. For the community to build the next killer app, we need solutions that are not just powerful but also affordable.
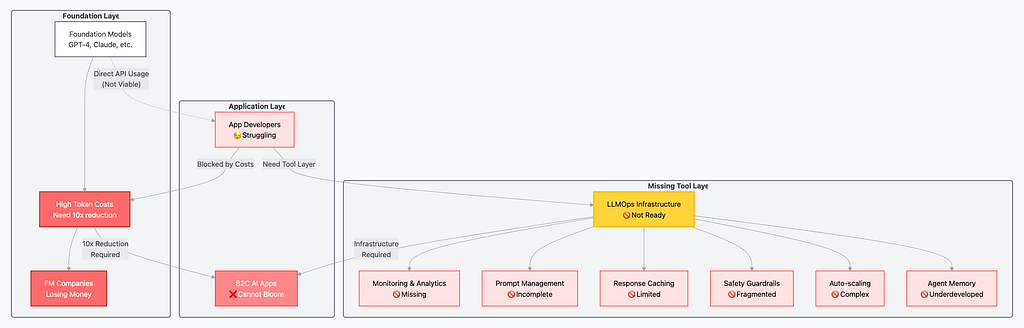 LLM-margin squeeze
LLM-margin squeeze
So, when I saw Emergence AI’s open-source code, my first question was: will this work with GPT-4o mini?
The answer is a resounding yes.
I love the simplicity of their demo — it’s basically a single main.py file. Getting started is a breeze:
- Clone the repo.
- Run pip install -r requirements.txt.
- Add your OpenAI API key and set the model to gpt-4o-mini.
- Run python main.py.
The first run showed a fantastic result. The script works beautifully with GPT-4o mini, achieving an accuracy of 71.2%. That’s a stunning outcome, as it’s the exact same score Zep achieved using the much more powerful and expensive GPT-4o!
A word of caution if you try this at home: watch your API bill. Running the full evaluation isn’t free.
- GPT-4o mini: ~$1.50
- GPT-4o: ~$30.00
If you just wanted to know who holds the current SOTA title, you have your answer. But my job is to see if a solution is robust and generalizable, not just a one-off success on a specific dataset. If you want to know how it really holds up, read on.
A Quick Detour: Making the Benchmark More Reliable
Before we go deeper, we need to talk about evaluation. In her book AI Engineering, Chip Huyen discusses how using an AI as a Judge became a major trend. While it’s useful for evaluating complex language tasks, this method can be inconsistent, expensive, and a bit tautological.
Since modern models handle structured output well, I’ve long advocated for using multiple-choice questions (MCQs). A 10-choice format makes evaluation objective and reliable. To that end, I created a 10-choice version of LongMemEval, which you can find here. Testing EmergenceMem Simple Fast with GPT-4o mini on this version gave us a nice performance bump to 76.8%.
To see how the solution holds up more broadly, I also ran it against my MCQ versions of two other popular conversation datasets: Multi-Session Chat (MSC) and LoCoMo. Here are the results:
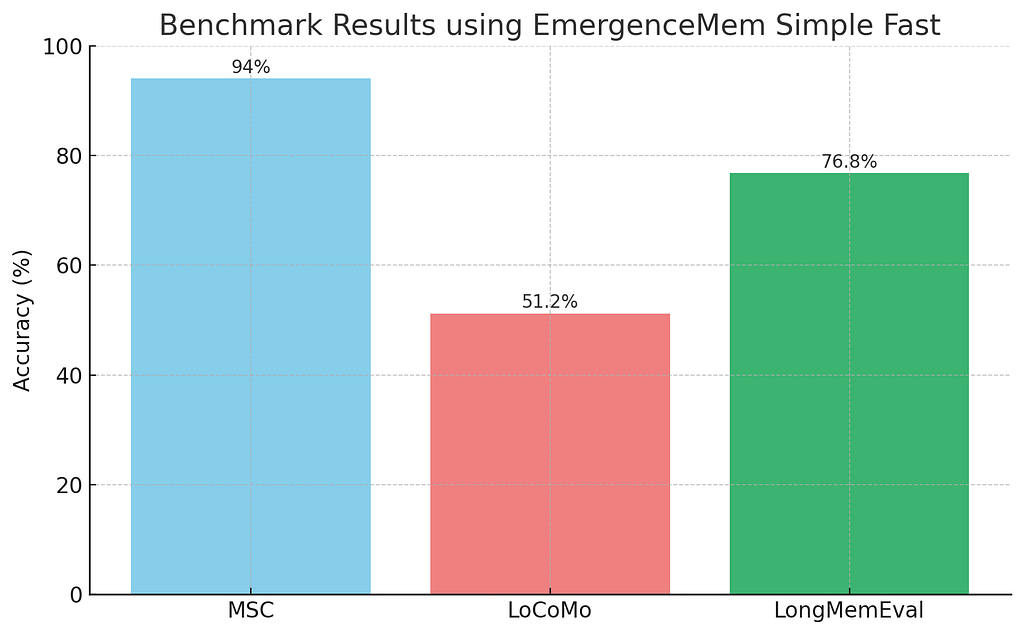 EmergenceMem Simple Fast on MSC, LoCoMo, LongMemEval
EmergenceMem Simple Fast on MSC, LoCoMo, LongMemEval
The high score on MSC is expected — it’s a relatively easy dataset. The score on LoCoMo, however, is a huge red flag.
This isn’t the first time the LoCoMo benchmark has raised eyebrows. The founder of Zep famously called out Mem0 in a post titled Lies, Damn Lies, & Statistics ), questioning their reported scores on the dataset.
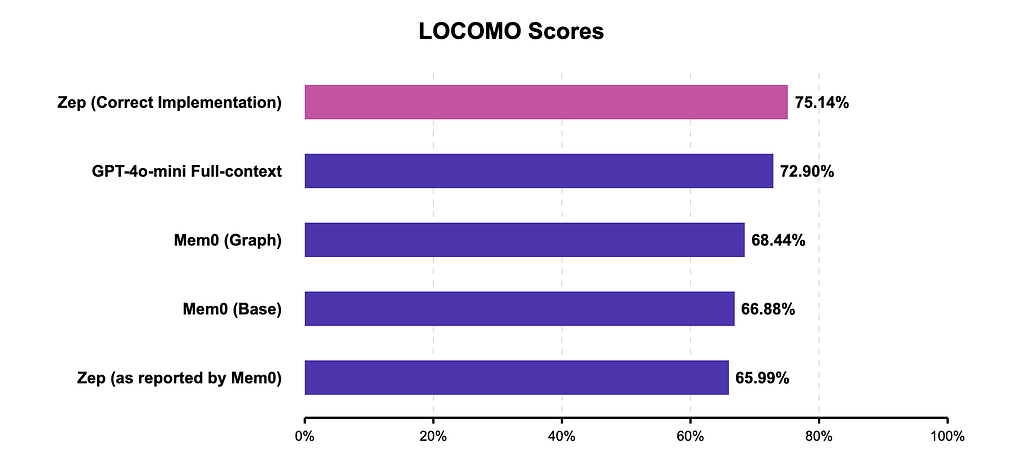 Zep vs. Mem0 on LoCoMo
Zep vs. Mem0 on LoCoMo
This brings us to a critical puzzle. LongMemEval is widely considered to be a much harder benchmark than LoCoMo. So why does the Emergence AI solution perform so much worse on the supposedly easier dataset?
The Culprit: A Hardcoded K
To understand the strange LoCoMo result, I had to dig into the code. My investigation focused on two of the most common culprits in any RAG system: chunking and Top-k.
The first, chunking, defines the size of your data units. The second, Top-k, determines how many of those units get retrieved to answer a query. The fundamental problem is that there is no universal setting for these parameters. Every dataset is different.
- Some documents are information-dense; others are repetitive.
- Some questions require broad context; others need one specific fact.
A fixed chunk size and k-value that work for one use case will almost certainly be suboptimal for another.
So, what did the Emergence AI code reveal? Their approach is refreshingly simple. They perform no explicit chunking, using each conversational turn as a natural data unit. And for the K value? They hardcoded it.
They set k=42 for everything.
I can appreciate the logic. A turn is a natural unit of conversation, and 42 is, of course, the answer to the ultimate question of life, the universe, and everything. It seems they chose to focus their energy on the core architectural challenges rather than getting lost in hyperparameter tuning.
But this fixed-k approach is almost certainly why the performance stumbled on LoCoMo. This is where the open-source community can shine. My goal isn’t to find fault but to see if I can build upon their fantastic work.
Beyond the Magic Number: An Adaptive-k Approach
To solve the “fixed k” problem, I developed a more dynamic and adaptive approach. My method is a three-step process:
- Set a Token Budget, Not a Chunk Count. Instead of retrieving a fixed k chunks, I first retrieve a large batch of candidates. Then, I enforce a hard limit on the total number of tokens (e.g., 8192) that can be included in the final context. This makes the process independent of the chunking strategy. 2. Ensure Diversity with MMR. I then apply the Maximal Marginal Relevance (MMR) algorithm to the initial results. This is crucial: it re-ranks the documents to create a balanced context, prioritizing items that are both highly relevant to the query and diverse from each other. This step is key to avoiding redundant information. 3. Select Adaptively with Top-p. Finally, instead of taking a fixed Top-p, I use Top-p (Nucleus) selection. This adaptively selects the most relevant documents whose cumulative relevance scores exceed a certain probability threshold, p. It’s a more intelligent method because the number of retrieved items — our “adaptive k”— changes dynamically for each query.
Visually, the process looks something like this:
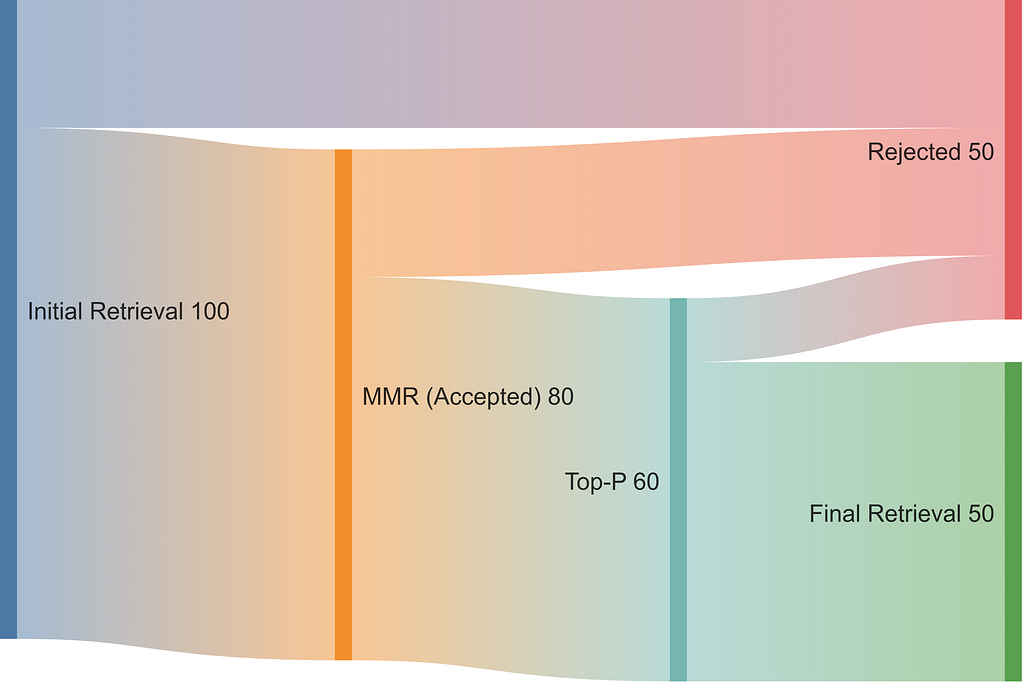 MMR + Top-p
MMR + Top-p
Of course, this approach introduces its own knobs to tune — namely, the MMR diversity parameter λ and the Top-P threshold p. However, these parameters control a dynamic process, allowing the retrieval size to flex based on need rather than being locked to a single number.
And the results speak for themselves:
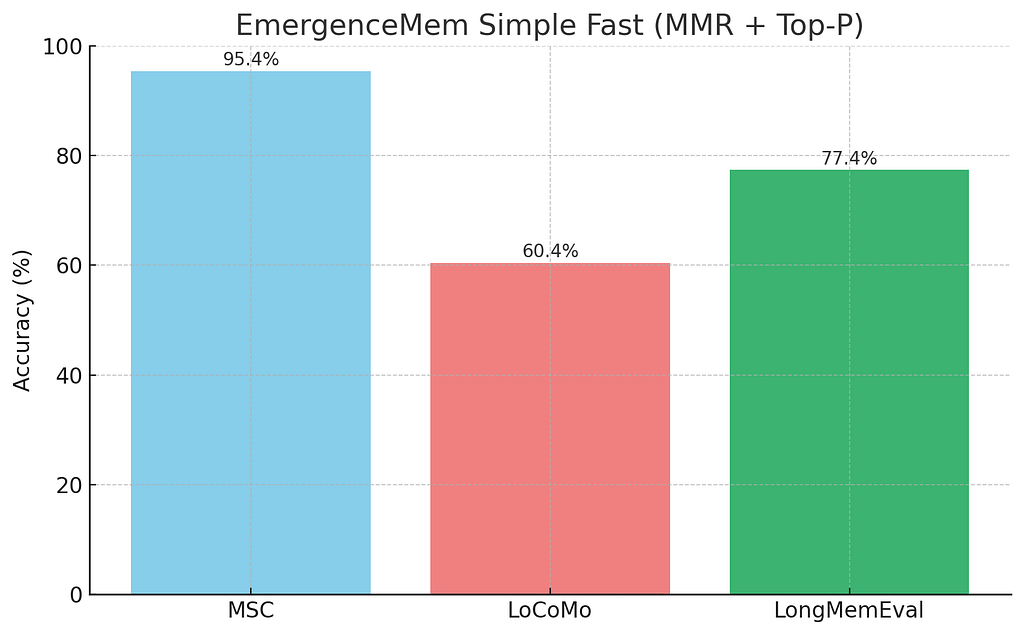 EmergenceMeme Simple Fast (MMR + Top-p) on MSC, LoCoMo, and LongMemEval
EmergenceMeme Simple Fast (MMR + Top-p) on MSC, LoCoMo, and LongMemEval
As you can see, performance improves on all three benchmarks, and the problematic LoCoMo score is now much healthier. The best part? You no longer have to worry about picking the “right” k every time you use a new dataset. The system adapts.
This performance bump does come at a cost, of course. On average, the number of retrieved items went from a fixed k=42 to a dynamic average of k=62.5. This, in turn, increased the cost of running the full evaluation on GPT-4o mini to $1.99 — a 42% increase. I guess that number really is the answer to everything. 😉
A closer look at the retrieval stats shows there’s still plenty of room for improvement:
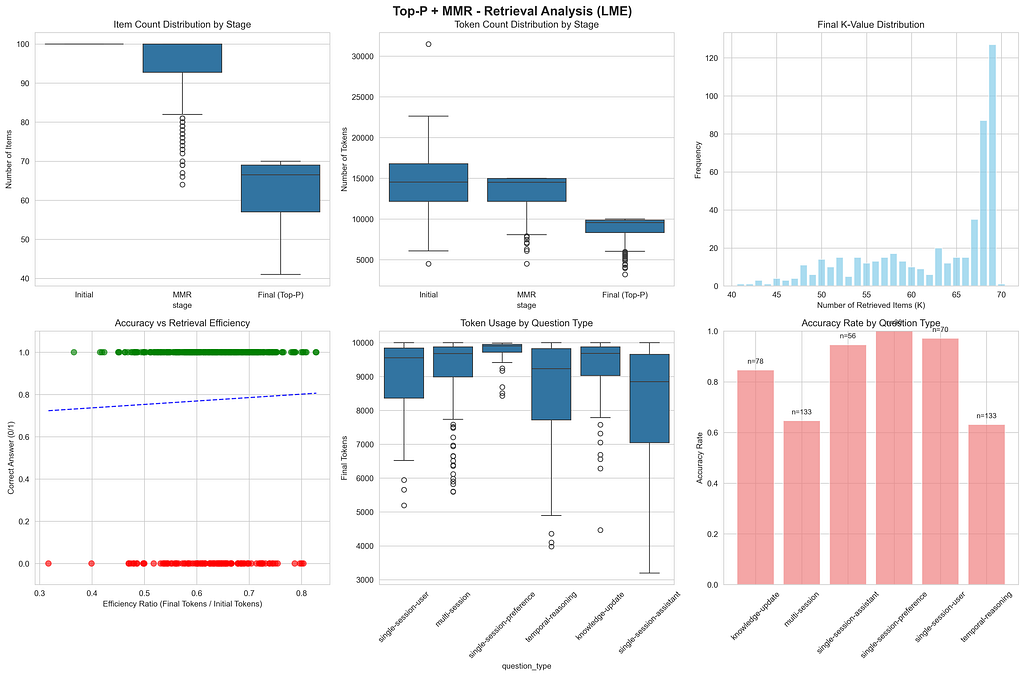 Retrieval Analysis (LongMemEval)
Retrieval Analysis (LongMemEval)
While our adaptive k varies, the distribution is skewed high, with the mode (most frequent value) sitting around 68. However, a quick regression shows that simply using more tokens doesn’t have a strong correlation with accuracy. This tells me the process can be made much more efficient — a perfect challenge for a future post!
Conclusion
This journey started with a simple goal: to understand Emergence AI’s new state-of-the-art result on LongMemEval. Their work is a huge step forward for agent memory, but a surprising performance dip on the LoCoMo benchmark pointed to a small but significant detail: a hardcoded retrieval limit of k=42.
This experiment shows that we can build on their impressive foundation. By swapping the fixed k for a dynamic, adaptive approach using MMR and Top-p, we see a clear win. Performance improved significantly across all benchmarks, and the system became far more robust. However, while the adaptive method fixed the initial performance drop on LoCoMo, the final score still falls short of the state-of-the-art results reported by competitors like Zep.
This lingering gap, even with a more flexible retrieval algorithm, strongly suggests the bottleneck has shifted from the algorithm to the data representation. My gut feeling is that the unique structure of the LoCoMo dataset is the key. Unlike standard user-assistant chats, it features dialogues between two distinct people (e.g., Caroline and Melanie). To fit this into a conventional format, I preprocessed the data by embedding speaker names directly into the content, like so:
[
{
"role": "user",
"content": "[CAROLINE]: Hey Mel! Good to see you! How have you been?"
},
{
"role": "assistant",
"content": "[MELANIE]: Hey Caroline! Good to see you! I'm swamped with the kids & work. What's up with you? Anything new?"
}
]
This approach, while functional, may confuse a retrieval system not specifically designed for multi-speaker turn-taking. Closing the final gap on a dataset like LoCoMo will likely require a more nuanced data preparation strategy.
This highlights that even with a flexible algorithm, data representation is key. And of course, this flexibility isn’t a free lunch — the adaptive method increased the average number of retrieved items, leading to a higher token cost.
Ultimately, this journey from a fixed k=42 to an adaptive k underscores a crucial principle: we should favor dynamic, context-aware components over static, “magic number” configurations. This adaptability is the key to creating solutions that are not just powerful, but also reliable and efficient.
I believe this is a promising direction, and there’s still so much to explore — from optimizing the cost-performance balance to developing better data strategies for complex dialogues. I’ve open-sourced my code with these modifications for anyone who wants to experiment further.
You can find the forked repository here: Emergence Simple Fast (Adaptive-K Fork)
What are your thoughts? Have you encountered similar issues with fixed retrieval parameters or similar challenges with multi-speaker datasets? Let me know in the comments below!
Originally published on Medium.