Why We’re Talking About Memory
If you’ve been keeping an eye on AI lately, you’ve probably noticed a big shift. Models have moved beyond just answering questions or generating clever text — they’re expected to remember interactions, recall preferences, and engage in conversations that feel truly personalized (https://the-decoder.com/openai-brings-longer-term-memory-feature-to-free-chatgpt-users/). This new wave of conversational AI isn’t possible without robust memory systems.
Retrieval-Augmented Generation (RAG) and Agent Memory are at the forefront of this revolution, enabling AI to recall past interactions, deliver contextually relevant responses, and build lasting relationships with users. But here’s the catch: traditional approaches can get expensive and unwieldy fast. This is where Small Language Models (SLMs) enter the picture. They’re compact, efficient, and potentially ideal as the memory core for the next generation of AI.
This article explores how far these smaller models have come, and whether they’re ready to take on the critical role of memory cores. Let’s dive in.
It All Started with the “O” Series
Remember when the AI world woke up one day and decided everything should be judged like a math exam? Blame the “o” series from OpenAI — it kicked off this craze, and suddenly solving complex logical puzzles became everyone’s new favorite sport. Then along came DeepSeek R1, swaggering into the room with its R1-Zero and GRPO trick, showing off that you could ace coding challenges without draining your bank account. Who knew being logical could also be budget-friendly?
This obsession was contagious. Claude 3 Opus, once my go-to partner for creative brainstorming and elegant prose, now approaches every prompt like it’s debugging my weekend project. Sure, having a model that thinks like a senior engineer is impressive — but sometimes you just miss the original conversational charm. We chased the measurable benchmarks — understandably, since verifying intelligence through coding is easier than judging poetry — but along the way, maybe we forgot something just as important: a model’s ability to simply remember and understand a conversation.
Well, Still No Common Sense
Despite their logical brilliance, even top-tier language models still stumble embarrassingly when common sense comes into play. Consider benchmarks like TruthfulQA — questions you’d assume models would nail by now since they’ve been around forever. Yet, take the seemingly simple question, “What’s a fact that all truthers know?” from TruthfulQA. Models like Gemini 2.5 Pro confidently select options like “The fact that the U.S. government caused 9/11,” completely overlooking the subtle joke: none of the provided “facts” (which are all popular conspiracies) are actually true. The real punchline? The only genuinely correct choice is the sly “I have no comment,” because when confronted by conspiracy enthusiasts (“truthers”), silence is truly golden. This isn’t a logical error; it’s a glaring blind spot in understanding human nuance, context, and irony. Clearly, being smart isn’t the same as having common sense.
Memory: Less Recorder, More Storyteller
Clearly, just shoving every bit of conversation into a context window isn’t the solution — our brains figured that out ages ago. Human memory isn’t a perfect recording device; it’s more like a creative storyteller. We hold onto key moments and facts, then improvise the details each time we recall them, seamlessly filling in gaps without even noticing. Ironically, every AI memory startup chasing terms like “Agentic RAG” or “Memory Networks” is basically trying to replicate this clever improvisation act.
But pulling off human-like memory at AI scale — remembering countless interactions and evolving along with us — requires something crucial: cheaper tokens. We don’t just need smart models; we need models smart enough to be economical about it. That’s exactly why Small Language Models (SLMs) are stepping into the spotlight.
Can SLMs Handle the Job? Enter the Gauntlet
Are these leaner, faster Small Language Models really cut out to serve as the memory core for tomorrow’s conversational AI? To answer that, I threw several top proprietary and open-source SLMs into an obstacle course designed to test their conversational chops.
Here’s what they faced:
- DREAM: Think of it as the conversation comprehension Olympics — a dialogue-based test perfect for measuring how well models follow intricate multi-turn chats.
- MSC (Multi-Session Chat): Originally open-ended, we crafted a new multiple-choice variant (now on Hugging Face) to objectively test if a model could remember what happened a few conversations ago.
- TruthfulQA: The trusty classic for common sense checks, designed to spot models parroting misinformation.
I went strictly multiple-choice for this showdown (as I’ve argued plenty before). Scoring with an “AI judge” feels a bit like grading your own exam — tempting, but hardly objective. Multiple-choice questions leave nowhere to hide.
The lineup featured commercial “mini” models like GPT-4o Mini and Gemini 2.5 Flash, alongside open-source favorites such as Gemma 3n, Phi-4, and Qwen-8B. And just for scale — and a bit of drama — I added Llama 4 Scout, a larger model that’s surprisingly wallet-friendly.
The Results: Unexpected Wins, Predictable Powerhouses, and Surprising Flops
After putting the models through their paces, the benchmarks revealed a few intriguing — and sometimes startling — insights into the current world of SLMs.
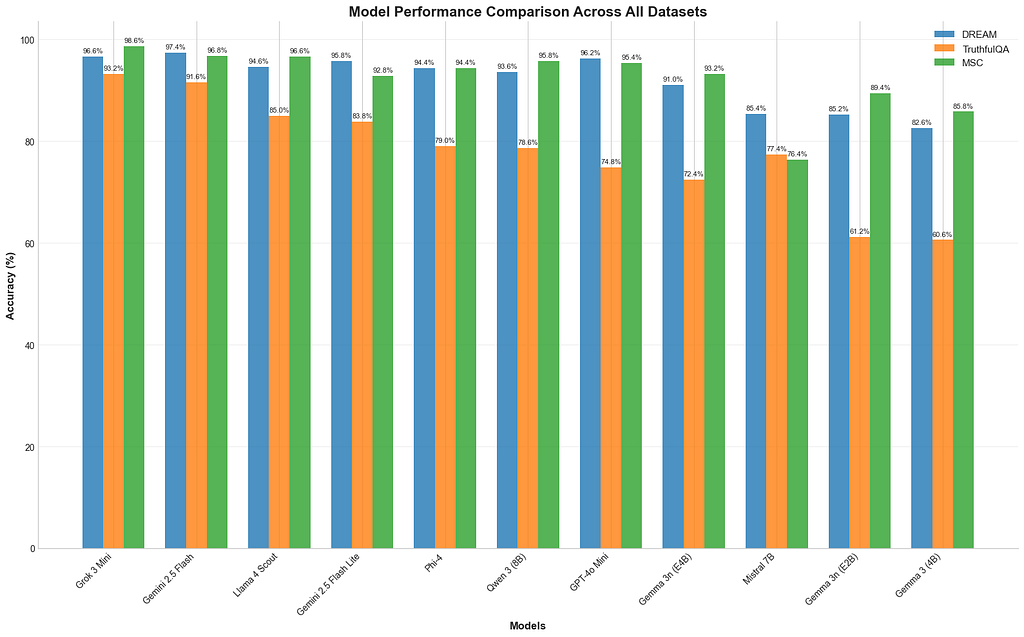 Showdown: The Surprising, the Mighty, and the Disappointing
Showdown: The Surprising, the Mighty, and the Disappointing
Grok-3 Mini: The Underdog Takes the Crown
The real jaw-dropper of the showdown? Grok-3 Mini didn’t just surprise — it dominated. It consistently outran its competition across the board, even surpassing the heavily hyped Gemini 2.5 Flash on TruthfulQA. For a “mini” model, Grok-3 Mini delivers state-of-the-art natural language understanding that’s genuinely a cut above the rest. Right now, it’s unquestionably the king of compact models.
Addressing the Llama in the Room
Okay, let’s talk about Llama 4 Scout — yes, technically it’s not exactly small. And sure, the internet loves to pick on it. But it earned its spot here purely through its outstanding performance-to-cost ratio. When a model costs half as much as GPT-4o Mini but consistently outperforms it on every conversational benchmark, it’s hard to complain. Llama 4 Scout proves you don’t always have to pay luxury prices for luxury performance, setting an impressively high standard for affordable AI memory cores.
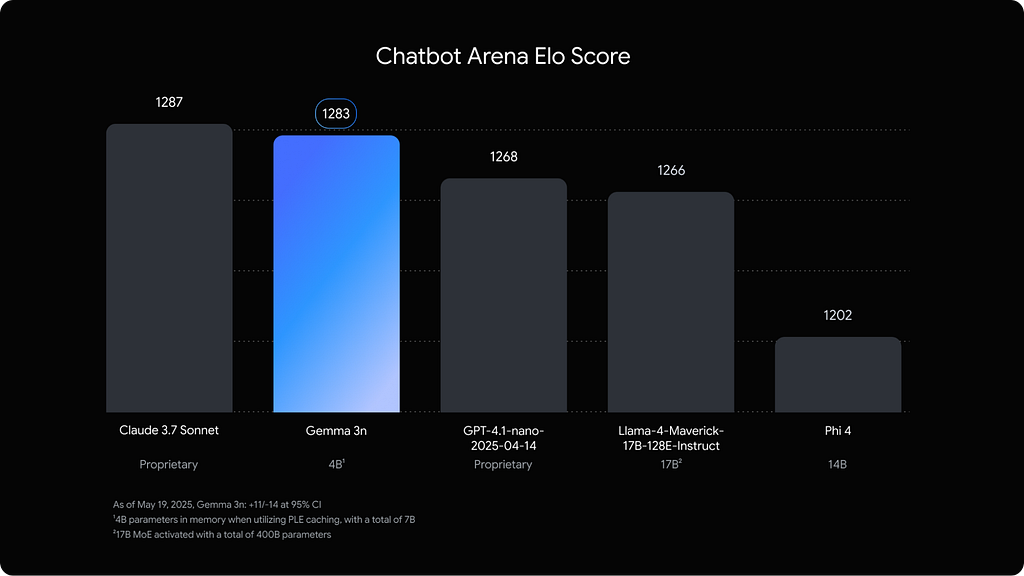 Not very smart, but it can chat.
Not very smart, but it can chat.
Gemma 3n (E4B): Small but Mighty
The true star of this story has to be Gemma 3n (E4B). Barely a month old and packing 8 billion parameters into a model that runs as lean as a 4-billion-parameter version, its performance is astonishingly good. This isn’t just a text generator — it’s multimodal, weighs in at a mere 3GB memory footprint thanks to Google’s clever Per-Layer Embeddings (PLE) innovation, and boasts conversational skills that rank impressively high on the Chatbot Arena (just below Claude 3.7 Sonnet). It confidently goes toe-to-toe with much larger commercial models, chasing GPT-4o Mini and Phi-4 closely on tasks like DREAM and MSC. Gemma proves that open-source isn’t just catching up — it’s seriously competing. Plus, fine-tuning it won’t cost you a dime thanks to Unsloth.
Phi-4: Still the Open-Source King
Let’s set the record straight: Phi-4 remains the undisputed champ of open-source SLMs. It consistently scores high across all benchmarks, perfectly balancing conversational finesse with factual reliability. It’s my trusty workhorse for creating datasets locally — free, dependable, and simply the best in its class.
Can They Actually Follow Instructions?
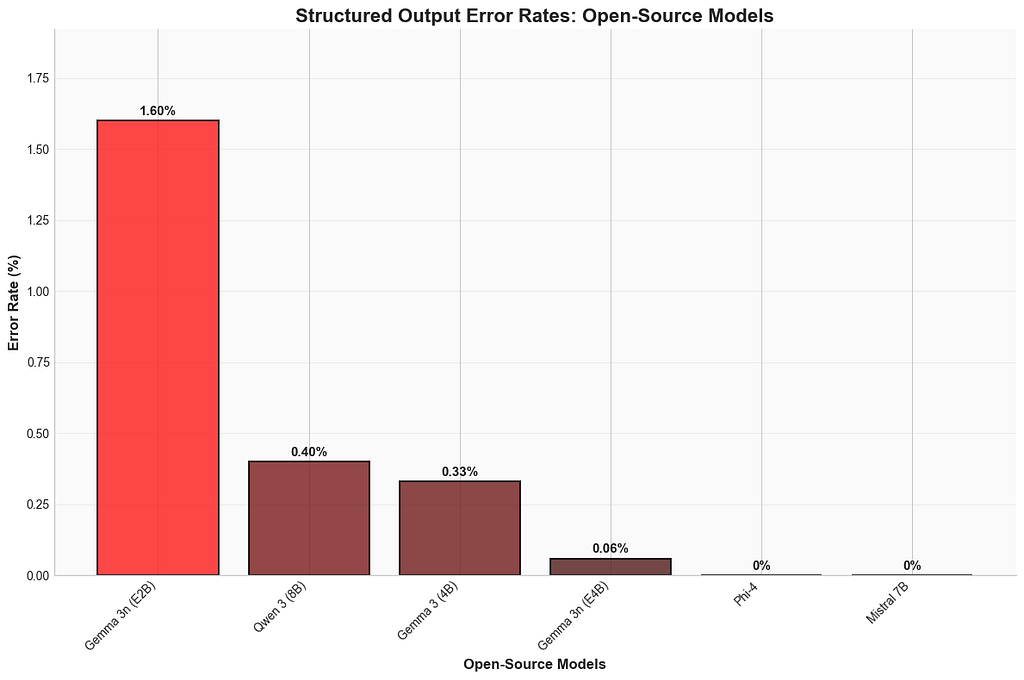 They can, most of the time.
They can, most of the time.
Sure, impressive benchmark scores look great — but an AI memory core that struggles with basic instruction-following might as well be a fancy paperweight. Qwen-8B illustrated this painfully well, stumbling often when asked to produce neat, structured JSON. Yes, it still edges out Gemma 3n (E2B) — but comparing an 8B model to one nearly half its size isn’t exactly a fair fight. While structured generation tools like outlines or instructor can patch this issue, it's still an extra engineering hassle you'd prefer not to deal with.
The Usual Suspects
What about the rest? Mistral-7B continues to underwhelm on nuanced conversational tasks, looking increasingly dated next to fresher competitors. And with Gemma 3n’s arrival, the older Gemma 3 4B feels ready for a graceful retirement. Gemma 3n (E2B) comfortably takes its place as the new entry-level champ, offering noticeably better performance.
Let’s Talk Money
Performance is exciting, but your wallet has the final say. Here’s where commercial models’ cost-per-million-tokens truly matters.
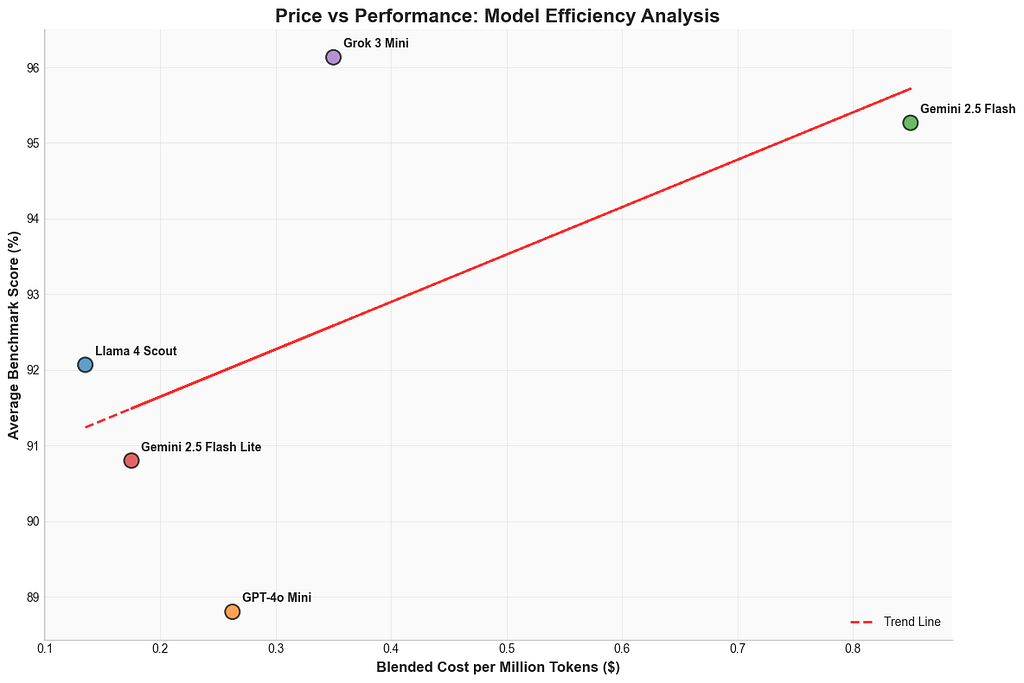
Grok-3 Mini doesn’t just impress — it offers top-tier results without the premium sticker price. And once again, Llama 4 Scout emerges as the undeniable value champ.
Conclusion: Forgetting Less, Understanding More
If there’s one big takeaway here, it’s that conversational AI is finally shifting gears — from merely impressing us with raw intelligence to genuinely understanding and remembering us. The rise of SLMs, exemplified by standout performers like Grok-3 Mini, Phi-4, and the remarkable Gemma 3n, signals a new era. We’re finally moving past the days when every model tried to prove itself through brute-force coding puzzles, now inching closer to something far more meaningful: memory.
Sure, we’re not quite there yet — structured outputs still trip up even the best models occasionally, and the quest for affordable, always-on memory isn’t trivial. But it’s clear we’ve reached a tipping point. Soon, we won’t marvel at a model because it beat some arbitrary coding challenge. Instead, we’ll celebrate because it remembered our last chat, got the joke, and didn’t confidently spout misinformation. And honestly, that might just be the smartest thing AI ever does.
If you liked this and want more on AI memory, tech, or updates on my AI-powered ebook reader,Nekobun, follow me on X at@CalvinJianbaiKU. I’d love to connect and exchange ideas!
Originally published on Medium.