
***Note:***This article was updated on September 2, 2025, to incorporate clarifications from Sarah, the founder of Letta. The original version categorized Letta as a type of advanced RAG. Sarah clarified that Letta’s primary focus is on context re-writing which can work in tandem with any RAG provider, rather than being a RAG provider itself. The section on latency has also been updated with her insights.
The “We’re Not RAG” Deception
Four months ago, AI startup Letta put out the article “RAG is not Agent Memory” to explain how what they’re doing is not RAG. To save you some time, here are the key takeaways:
- Context Pollution: RAG introduces too much irrelevant data into the context window, which can harm the LLM’s reasoning abilities.
- Single-Step Process: RAG performs a single retrieval and generation, which is insufficient for complex tasks that require a deeper understanding of the source material.
- Purely Reactive: RAG retrieves information based on simple semantic similarity to the immediate prompt, failing to connect contextually relevant but semantically distant information (e.g., connecting a user’s favorite color mentioned previously to a current conversation about their birthday).
- How Letta’s “Agentic RAG” is Different: Their multi-step, agentic RAG is different and solves all the problems mentioned above.
What I like about this article is that it highlights the importance of agent memory — something most developers probably bump into when they try to build anything on top of an LLM. What I don’t like about the article is everything else it says. This is the wrong way to stress the importance of Agent Memory: by attacking a straw man.
Funnily enough, five days ago, another AI startup, Zep, published “Stop Using RAG for Agent Memory,” preaching their version of how RAG is terrible and how they’re not RAG.
- No Temporal Awareness: RAG systems cannot distinguish between old and new information, often retrieving outdated facts.
- Inability to Understand Causality: They fail to grasp the relationships between events, such as a change in preference due to a negative experience.
- Fact Invalidation: RAG cannot effectively handle situations where a fact is no longer true.
- How Zep’s “Graph RAG” is Different: A RAG that uses a knowledge graph underneath solves all the problems mentioned above.
I don’t think I have to repeat myself to explain why I don’t like this article. It’s simple:
Both Letta and Zep are RAG that are trying to pretend they’re not.
This reminds me of what Peter Thiel says in Zero to One:
“Monopolists lie to protect themselves. They know that bragging about their great monopoly invites being audited, scrutinized, and attacked….Non-monopolists tell the opposite lie: “we’re in a league of our own.” Entrepreneurs are always biased to understate the scale of competition, but that is the biggest mistake a startup can make.”
Don’t get me wrong. I like what Letta is doing; I think I’ve stressed that many times in my previous articles. I also think Zep has the best approach so far to tackling the problem of temporal reasoning. And I totally agree that Agent Memory isn’t RAG. And that’s the problem. Agent memory isn’t RAG, but for totally different reasons than they suggest.
Getting It Right: RAG is a Solution, Memory is the Problem
Yeah, it’s that simple. To say one is not the other is a category mistake. And I don’t think they made that mistake by accident. The way they put it is like saying: Oh, RAG is so low-tech that everyone knows how to do it. Nah, we’re absolutely not doing that. We’re a lot more than that. That’s what I don’t like.
Myth-busting: RAG Is Not a Low-Tech Toy
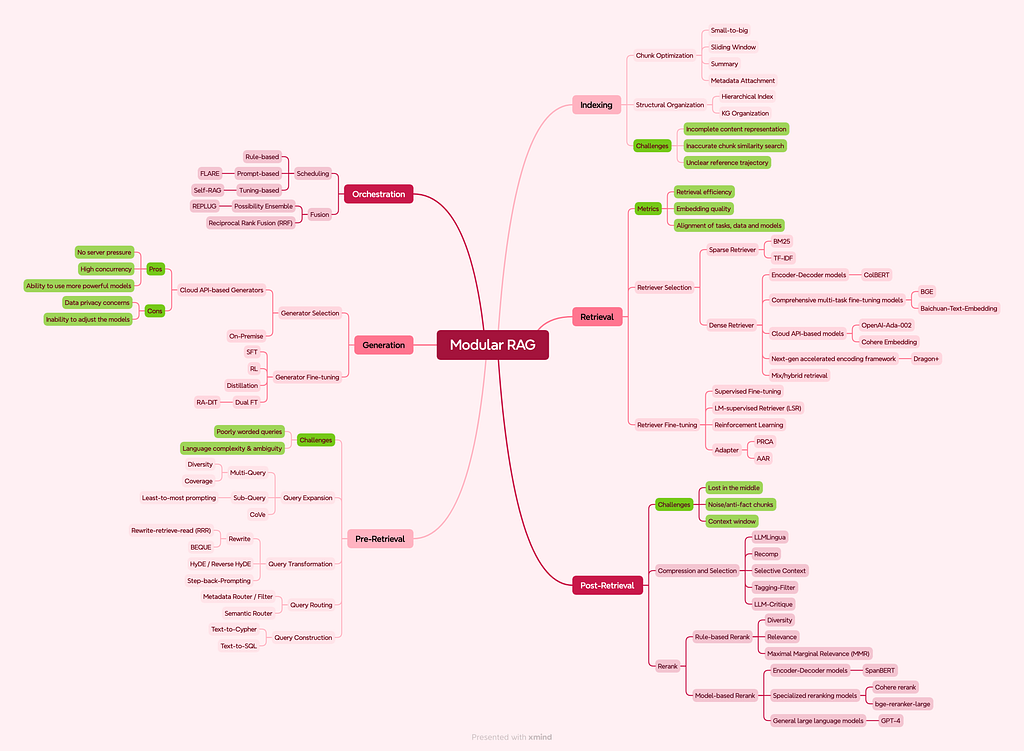 Everything You Need to Know about Modular RAG
Everything You Need to Know about Modular RAG
I made this mind map a few months ago when the word “agentic” was hardly used by anyone (crazy, right? Things that everyone takes for granted now didn’t even exist a few months ago). Since then, I’m sure substantial updates could be made to the map, but you get the idea. What we now call “Agentic RAG” was more often referred to as “Modular RAG” (with orchestration) back then by the RAG people. While I previously grouped Letta’s approach here, their founder clarified that they focus on context re-writing (inspired by concepts like MemGPT) which can connect to any RAG tool, rather than being a RAG provider. This is an important distinction. Zep’s Graph RAG, however, is a clear and powerful evolution of the RAG paradigm. The broader point stands: these advanced systems are built upon the foundational principles of retrieving, augmenting, and generating.
The AI Memory Landscape: Where RAG Truly Fits
Like I said, it’s as wrong to say RAG isn’t AI memory as it is to say that RAG is AI memory. In the paper LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, the authors put the approaches to AI memory into three categories:
- In-Context Learning: Adapting LLMs to process extensive history as long-context inputs.
- Memory Networks: Integrating differentiable memory modules into language models.
- RAG: With context compression, with embeddings, with discrete tokens. RAG of all kinds.
To give memory to AI, we don’t need to restrict ourselves to just RAG. Among the three categories, Memory Networks are the sexiest and probably the future direction of many AI unicorns. In-Context Learning is the least sexy, but it’s something that anyone can use, and for many use cases, it’s good enough. RAG lies somewhere in the middle and is probably the most feasible approach right now. This is why, while these startups claim otherwise, all of them are going with a RAG approach. From a research perspective, it’s probably not that interesting. But to get it to work involves a lot of engineering magic.
If you’re not very familiar with RAG, the authors of that paper also formulate a three-stage model to provide a unified view of how RAG works.
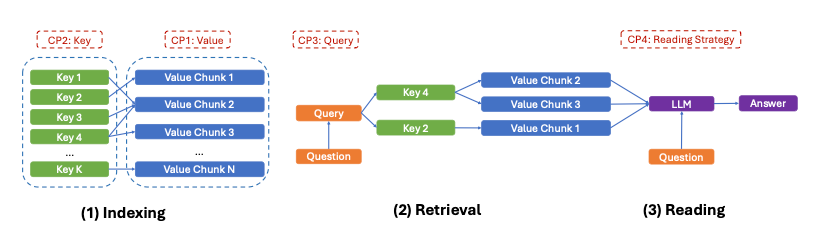
The Real Challenge: What Makes Agent Memory So Hard?
In my opinion, the limitation of RAG lies in the first stage: Indexing, or more specifically, the first control point: how we chunk text. There are infinitely many ways we can chunk a piece of text, and there’s no one right way to do it. Also, the way computers store text makes it very difficult to update the values. In this sense, a Knowledge Graph seems like a natural choice for dealing with the problem. Still, it’s very hard to get it to work properly. Next, I’ll lightly touch on the major problems when trying to give AI agents memory.
The Five Hurdles from Academia
In LongMemEval, the authors classify the problems into five categories:
- Information Extraction (IE): Recalling specific information from extensive histories.
- Multi-Session Reasoning (MR): Synthesizing information across multiple sessions.
- Knowledge Updates (KU): Recognizing and updating user information dynamically.
- Temporal Reasoning (TR): Awareness of the temporal aspects of information.
- Abstention (ABS): Knowing when to say “I don’t know.”
In case that’s hard to understand, the authors were considerate enough to provide a very detailed illustration to showcase the problems of each category.
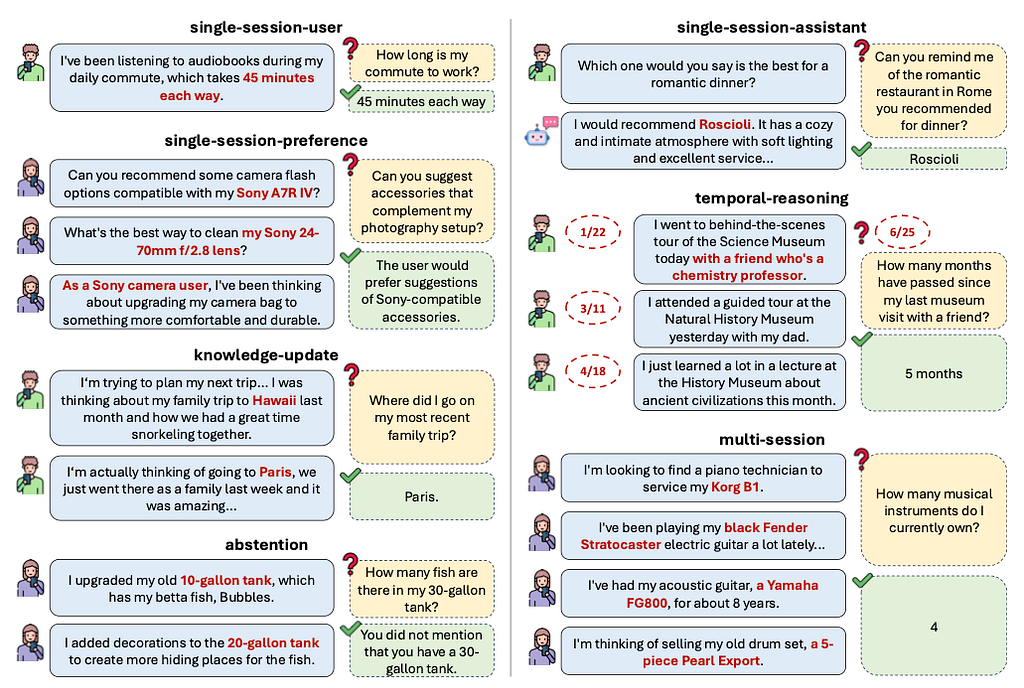 Five Core Long-Term Memory Abilities
Five Core Long-Term Memory Abilities
Most of these are actually very difficult problems. If you don’t have these problems in mind when building a RAG, it’s almost certain your RAG won’t be able to deal with them. In January, Zep published a paper claiming that they’ve tackled 45.1% of temporal reasoning problems and 78.2% of knowledge update problems. I’ve already stated my opinion elsewhere on that paper (it looks like a marketing brochure disguised as a technical report), but if they’re not faking their results, this is a truly remarkable achievement. I don’t think other commercial competitors like Letta or Mem0 can get a result that’s anywhere close.
Three More Headaches from the Real World
The LongMemEval paper is very thorough and establishes a framework for us to talk about the memory problem more systematically. If you’re interested in the memory problem, I highly recommend you read it.
That said, there are a few important aspects not addressed in the paper:
- Dynamic Information Ingestion
- Latency
- Knowledge Conflict
Dynamic Information Ingestion
Like I said earlier, I believe chunking is the biggest bottleneck we’re facing, limited by our current storage technology. If you search on Google or YouTube, you’ll find people talking about all kinds of chunking methods. But they all discuss it in a non-dynamic setup; that is, they already have all the text, so all they need to think about is how to chunk it. In the real world, data arrives in real-time. We don’t know when it will come, how much will come, or if any more will follow. Without knowing all that, chunking can be very difficult.
Latency
A common concern with multi-step, agentic systems is latency. However, where that latency comes from can be misunderstood. For example, Sarah from Letta clarified that a tool call like send_message doesn’t necessarily add latency overhead, because an LLM API call needs to happen anyway. For a system like theirs, the more significant latency can come from being write-heavy — persisting state to a database for long-term memory. This highlights a critical trade-off in memory systems: ensuring robust, persistent memory can introduce delays, though modern engineering practices like using an async client can help mitigate these issues significantly.
Knowledge Conflict
In an age where fake news is everywhere, we as humans are used to the idea that information floating around us is only partially true. The good news is our minds can deal with that. The bad news is engineers familiar with databases are accustomed to the idea that they are storing “facts” in those databases. You’ll see knowledge graph people use the term “fact” quite often. I don’t mind the term, but I think it’s important to know that we are NOT storing facts. We’re storing what we believe to be highly likely true in some sense, all of which is subject to change. That’s what our minds store. And for Agent Memory to work like a human mind, that’s what we need to be storing for the agents as well.
Afterword: My Stake in the Memory Game
I became interested in Agent Memory when I first started building Nekobun, an AI-powered ebook reader. The dream is to have charming cat characters who don’t just comment on the text, but engage in genuinely insightful conversations with the user — remembering past discussions, preferences, and shared moments to create a truly personalized experience. That kind of personalization hinges entirely on a robust, reliable memory system. After looking around for a solid solution, I realized that this crucial aspect of building AI apps just isn’t there yet. I decided to pause for a bit and research the topic myself to get to know it better. I’ll keep sharing my findings here and would love to connect with you if you’re also interested in the topic.
If you liked this and want more on AI memory, tech, or updates on my AI-powered ebook reader,Nekobun, follow me on X at@CalvinJianbaiKU. I’d love to connect and exchange ideas!
Originally published on Medium.