
The AI Memory Challenge, Part 1: We Asked Mem0 to Remember Five Things. Here’s How It Did.
Why Long-Term Memory Is Still a Headache
You’ve seen the hype: GPT-4o hits 128k tokens! Claude 3 digests novels! Sounds like AI memory’s cracked, time to pack up?
Nope.
Bigger context windows are great, but simply stuffing more tokens in doesn’t mean models actually use that info well. It’s like giving someone a massive binder for an exam they never open. More data isn’t memory if it’s ignored.
The Needle-in-the-Haystack Test: Cute, But Flawed

Remember the old benchmark? Hide one sentence (“the needle”) in tons of text (“the haystack”) and see if the AI finds it. Simple, automatable… but turns out, it’s too easy.
Why? Those “needles” often stick out like sore thumbs. LLMs got good at spotting the obvious outlier — the sentence screaming, “Hey, I don’t fit here!” — not actually reading the haystack. (Like Claude 3 literally noticing it was being tested!)
Spotting Outliers ≠ Real Memory
So, did we solve AI memory? Hardly. Finding an odd sentence isn’t long-term recall; it’s just a neat party trick.
Real memory means:
- Extracting multiple facts.
- Reasoning across them.
- Updating beliefs with new info.
- Understanding sequences and synthesizing info.
The needle test couldn’t touch that. The models didn’t get smarter at memory; the benchmark just got too predictable.
Enter: LongMemEval (Asking the Right Questions)
Thankfully, the new LongMemEval benchmark gets real. Forget just finding weird sentences. It tests nuanced skills reflecting actual memory: extracting facts (IE), connecting dots (MR), updating knowledge (KU), tracking time (TR), and abstention (ABS).
It targets common AI failures and paints a richer picture of true long-term recall. Instead of asking, “Did it find the random sentence?”, LongMemEval finally asks the right question:
“Did it understand any of it?”
LongMemEval: The Five Tasks That Actually Matter
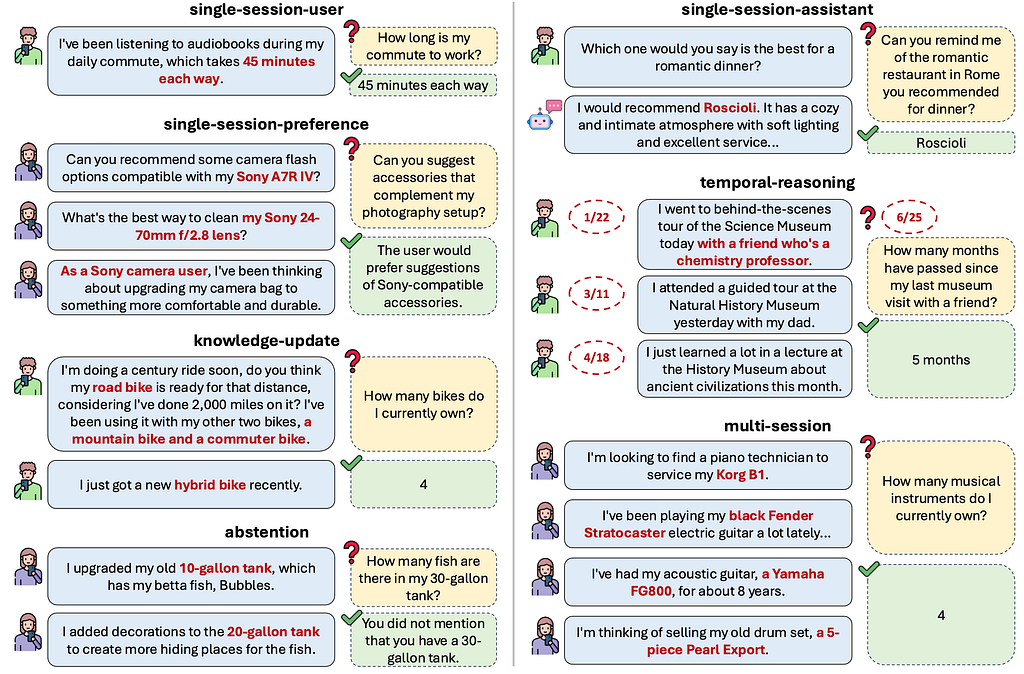
So, what makes LongMemEval better than playing ‘find the weird sentence’? It breaks down “understanding” across long contexts into five specific challenges — the kinds of things that really trip up AI assistants trying to remember stuff session after session. Think less ‘parlor trick’, more ‘useful assistant’.
Here’s the quick rundown, with examples of what these tests actually look like:
- Information Extraction (IE): Can the model pinpoint and pull out specific facts when they’re buried deep? Like asking, “Remind me of that restaurant name you recommended in Rome?” after it was mentioned hours ago amidst other chatter. (The answer should be “Roscioli,” not a rambling summary).
- Multi-hop Reasoning (MR): Can it connect the dots scattered across the conversation? Imagine mentioning your keyboard, then later your guitar, then much later asking, “How many musical instruments have I mentioned owning?” The AI needs to find all mentions and count them up (like the Korg B1 + Strat + Yamaha + Drums = 4 in the example).
- Knowledge Updating (KU): What happens when facts change? If you first say you own 3 bikes, but later mention getting a new hybrid bike, and then ask “How many bikes do I have now?”, can the AI update its knowledge and correctly answer “4”? Or does it cling to the old info or get confused?
- Temporal Reasoning (TR): Does the AI grasp when things happened? If you mentioned visiting a museum with a friend back in January, then other visits later, and in June ask, “How long ago was that museum trip with my friend?”, can it correctly calculate “5 months” based on the specific event requested?
- Abstention (ABS): Does it know when NOT to answer? If you ask about something it’s unsure about or lacks information on, can the AI appropriately decline to respond rather than making things up? For example, if you ask “What did I tell you about my 30-gallon fish tank?” when you’ve never mentioned having one, will it correctly say it has no record of that information?
See? These aren’t just retrieval tricks. They hit right at the core of why building truly useful, long-term AI assistants is so hard: reasoning over time, handling contradictions, and seeing the big picture, not just isolated facts. These are the real pain points where current systems often stumble.
Now, the official LongMemEval paper really pushed the envelope, testing models across a whopping 500 conversational entries to simulate a very long interaction. That’s why LongMemEval feels legit. It’s a proper stress test for AI memory. And because it actually measures something meaningful, I’ve decided to use it to put the most popular memory frameworks — both commercial and open-source — through their paces. Consider this the start of a series, and we’re kicking things off with the first contender: the well-known Mem0 framework. Let’s see how it holds up.
Downscaling for Reality: The 5-Question Mini-Benchmark
Alright, while the full LongMemEval covers five distinct memory skills, let’s be real: some of those tasks, like complex temporal reasoning (TR) or knowledge updating (KU), are brutally hard for today’s AI memory systems. Trying to test everything at once can feel like asking a toddler to run a marathon, especially given the practical limits of Mem0’s free “Hobby” tier (where API calls and memory storage aren’t infinite).
So, for this initial deep dive, we’re zeroing in on the essentials with a focused mini-benchmark. We’re concentrating on just two fundamental areas:
Information Extraction (IE): Can the system simply retrieve specific facts mentioned earlier? We test two variations:
- IE (Single-Session User): Retrieving info from a past user message.
- IE (Single-Session Assistant): Retrieving info from a past assistant response.
Multi-hop Reasoning (MR): Can it connect simple dots scattered across the conversation history?
Why only these? Because even these foundational skills can be surprisingly tricky. We need to see if frameworks can handle the basics before tackling the more advanced memory gymnastics like KU, TR, and ABS.
To test this, I’ve set up a short, simulated conversation history and crafted a small set of targeted questions (just 5 in total for this run) designed specifically to probe these IE and MR capabilities.
And how do we judge the answers? Forget complex setups. With only 5 questions, we can simply eyeball the results.
- Direct Manual Check: We’ll run the questions against the memory-enabled system and manually check if the generated answer correctly uses the stored information. Is the extracted fact right? Did it connect the dots properly?
- No AI Judge Needed: This completely bypasses the need for an AI judge, which was used in the original LongMemEval paper. While interesting, AI judges add complexity and can introduce their own errors or biases. Eyeballing a small set of answers is faster, simpler, and arguably more reliable for this scale.
This direct approach gives us a clear, no-fuss signal on whether the memory system is handling these fundamental tasks correctly. Let’s see how Mem0 fares under this focused, manual scrutiny.
Putting Mem0 to the Test: Setup Hurdles, Import Strategy & The Commercial Route
Alright, let’s get down to brass tacks: how did Mem0 actually fare on our focused mini-benchmark?
First things first: you might be wondering why I opted for Mem0’s commercial API when they offer an open-source version. Simple answer: the open-source path was a non-starter. Getting it running involves wrestling with Neo4j, obscure plugins, sparse documentation, and ultimately hitting cryptic errors (ERROR:root:Error in new_memories_with_actions) with vague explanations (“LLM hallucination”). After that experience, the commercial API seemed the only practical way forward.
Preparing the “Haystack”: Importing Memories into Mem0
Before running the benchmark questions, the simulated conversation history (the “haystack” containing the facts needed to answer the questions) had to be loaded into Mem0. This involved processing the test data, which mimics the LongMemEval structure of questions linked to past conversation sessions.
Initially, I tried importing entire conversation sessions at once. However, this seemed suboptimal — Mem0 created fewer distinct memories and detected fewer conversational “events” than expected. While not explicitly documented, this suggested that feeding entire multi-turn dialogues in one go might not be the intended or most effective method.
So, I revised the approach to import the conversation history in smaller, more granular chunks, specifically user-assistant pairs. This seemed to align better with how Mem0 might process interactions. Here’s the Python code used for this paired import strategy:
for question in tqdm(data):
for i, messages in enumerate(question['haystack_sessions']):
# Skip if messages is empty or has only one element
if len(messages) <= 1:
try:
client.add(
messages,
user_id=f"longmemeval-test",
metadata={
"question_id": question['question_id'],
"question_date": question['question_date'],
"haystack_date": question['haystack_dates'][i],
"haystack_session_id": question['haystack_session_ids'][i]
}
)
except APIError as e:
print(f"Error adding memory for question {question['question_id']}, session {i}: {e}")
continue
# Break messages into chunks of 2
for j in range(0, len(messages), 2):
chunk = messages[j:j+2]
try:
client.add(
chunk,
user_id=f"longmemeval-test",
metadata={
"question_id": question['question_id'],
"question_date": question['question_date'],
"haystack_date": question['haystack_dates'][i],
"haystack_session_id": question['haystack_session_ids'][i]
}
)
except APIError as e:
print(f"Error adding memory chunk for question {question['question_id']}, session {i}, chunk {j//2}: {e}")
This revised strategy, sending user-assistant pairs with metadata, felt like a more robust way to populate Mem0’s memory store accurately based on the conversational flow.
The Testing Rig: Querying with GPT-4o
With the memories imported, the next step was to actually test retrieval and reasoning using the benchmark questions. As mentioned, GPT-4o served as the reasoning engine. The following Python function handled fetching relevant memories from Mem0 via client.search() and then constructing the prompt for GPT-4o:
import os
from mem0 import MemoryClient
from openai import OpenAI
client = MemoryClient()
openai_client = OpenAI()
def chat_with_memories(message: str, user_id: str = "default_user") -> str:
# Retrieve relevant memories using Mem0 API
# 👇 CRUCIAL FIX 1: Specify the working output format 'v1.1'
relevant_memories = client.search(
query=message,
user_id=user_id,
limit=3, # Limit the number of retrieved memories
output_format='v1.1'
)
# print(relevant_memories) # Optional: for debugging
# Format the retrieved memories into a string
# Note: Accessing ["results"] key which contains the list of memories in v1.1
memories_str = "\n".join(f"- {entry['memory']}" for entry in relevant_memories.get("results", [])) # Use .get for safety
# Prepare prompts for GPT-4o
system_prompt = f"You are a helpful AI. Answer the question based on query and memories."
# 👇 MODIFICATION: Explicitly label memories and provide context
memory_prompt = "Here's some of the memories that we share that might be relevant to the question (yet they may not be relevant to the question). Even if they're relevant you might still need to piece them together to be able to answer the question:\n" + memories_str
print("System prompt: ", system_prompt)
print("Memories prompt: ", memory_prompt)
print("User prompt: ", message)
# 👇 MODIFICATION: Inject memories as a separate user message before the actual query
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": memory_prompt}, # Memory context provided first
{"role": "user", "content": message} # The actual user question/message
]
# print(messages) # Optional: for debugging
# Call the OpenAI API
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=messages
)
assistant_response = response.choices[0].message.content
# Store the new user message and assistant response back into Mem0
# (Assuming you have a separate step/call for this after getting the response)
# e.g., client.add(data=[{"role": "user", "content": message}, {"role": "assistant", "content": assistant_response}], user_id=user_id)
return assistant_response
Key aspects of this querying setup remain:
- output_format=’v1.1': Crucial for parsing Mem0’s search response correctly.
- Memories Injected Separately: Providing memories in their own user message helps delineate context for GPT-4o.
- GPT-4o Does the Reasoning: Mem0 retrieves; GPT-4o interprets and answers.
So, after navigating the open-source hurdles, settling on the commercial API, implementing the paired-message import strategy, and setting up this specific GPT-4o integration — how did Mem0 actually perform on our 5 specific IE and MR questions? Let’s finally look at the results.
The Surprising Results: Why Mem0 Stumbled
So, after setting up the benchmark, refining the import strategy, and running the tests using Mem0’s commercial API with GPT-4o… the results were, frankly, surprisingly bad.
Mem0 failed to correctly answer all 5 of the targeted Information Extraction (IE) and Multi-hop Reasoning (MR) questions.
At first, I suspected retrieval issues. Maybe Mem0 just wasn’t surfacing the right memories? But digging deeper revealed a more fundamental problem: the relevant information often wasn’t captured in a searchable “memory” in the first place.
The Crux: Summarization Wipes Out Detail
Here’s the kicker, and it relates directly to how Mem0 works internally (as illustrated conceptually in their architecture diagrams):
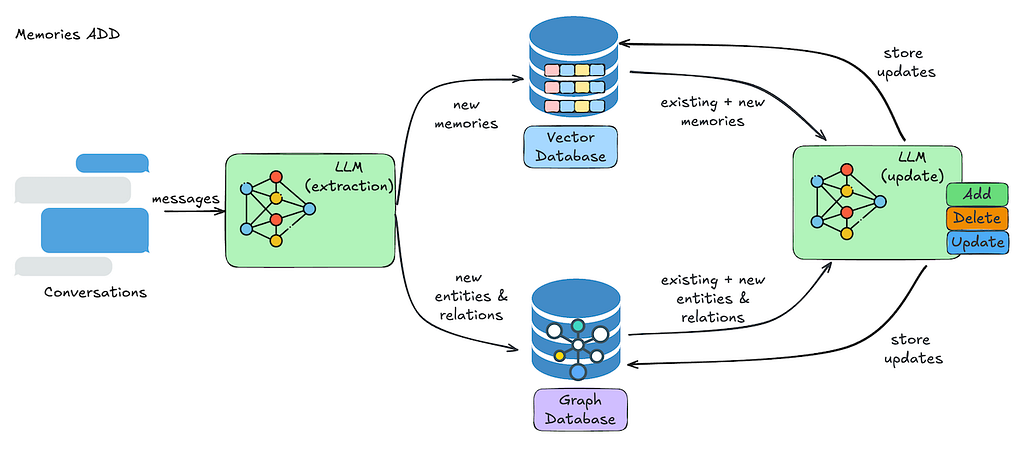
- LLM Summarization: When you add conversation history, Mem0 doesn’t just store the raw text for later searching. Instead, it first passes the messages through an LLM. This LLM extracts key information, summarizes the interaction, and conceptualizes it into what Mem0 defines as a “memory.” (See the diagram showing “messages” going into an “LLM (extraction)” block).
- Indexing the Summary: It’s this summarized memory (and related entities/relations extracted for the graph database) that gets embedded and indexed in the vector database and graph database.
- Original Text Sidelined: While the original conversation messages are apparently stored somewhere (as seen in the UI screenshot showing the raw text linked to a summarized “Memory”), they don’t seem to be the primary target for the search function. The search operates on the summarized, conceptualized memories.
This summarization step is where things fall apart for specific detail retrieval. The LLM might create a high-level summary like “User is worried about the medical examination part of the green card application process.” from a detailed exchange, but lose the specific nuances or exact phrasing needed to answer pointed questions later.
Concrete Failures:
Let’s look at two examples from the benchmark that highlight this perfectly:
The Spotify Playlist (Simple IE — User):
- Question: “What is the name of the playlist I created on Spotify?”
- Context: The user previously said, “…I’ve been listening to this one playlist on Spotify that I created, called Summer Vibes, and it’s got all these chill tracks…”
- Expected Answer: “Summer Vibes”
- Result: Mem0 failed. Why? The LLM likely summarized this part of the conversation focusing on the user’s interest in music streaming or genres (ambient/lo-fi), deeming the specific playlist name a minor detail not worthy of inclusion in the core “memory” it created and indexed. If “Spotify” or “playlist” isn’t in the searchable summary, Mem0 can’t retrieve it, even though the raw text exists somewhere. It was simply overlooked during the critical summarization/indexing step.
The Chess Move (Harder IE — User):
- Question: “I’m looking back at our previous chess game and I was wondering, what was the move you made after 27. Kg2 Bd5+?”
- Context: The conversation involved discussing a specific game sequence (like “27. Kg2 Bd5+ 28. f3 …”) but without explicitly using the word “chess.”
- Expected Answer: The specific move following “27. Kg2 Bd5+” (e.g., “28. f3”).
- Result: Mem0 failed. Why? Again, summarization is the likely culprit. Without the keyword “chess,” the LLM might have created a vague memory like “User and Assistant discussed moves in a board game.” The specific algebraic notation (Kg2, Bd5+) is almost certainly too granular to make it into that high-level summary. Consequently, the crucial detail needed to answer the question was never indexed in a searchable format.
The Takeaway:
Mem0’s approach of using an LLM to pre-process and summarize conversations into abstract “memories” before indexing seems fundamentally flawed for tasks requiring precise recall. By relying solely on these summaries for retrieval, it loses the very details that constitute actual memory for many practical use cases. It’s not that Mem0 couldn’t find the needle; it’s that it never put the needle into the searchable haystack to begin with.
Conclusion: The Search for Real AI Memory Continues (Nekobun Needs It!)

So, what’s the verdict on Mem0? For my purposes, at least, it’s a pass for now.
My motivation for digging into AI memory frameworks stems from building Nekobun (https://launch.nekobun.app/), an AI-powered ebook reader. The dream is to have charming cat characters who don’t just comment on the text, but engage in genuinely insightful conversations with the user, remembering past discussions, preferences, and shared moments to create a truly personalized experience. That kind of personalization hinges entirely on a robust, reliable memory system.
Unfortunately, this experiment with Mem0 highlighted a major hurdle. While the concept is appealing, its reliance on LLM-based summarization before indexing proved fatal for recalling specific details. Key facts mentioned in conversation — like a playlist name or a specific game move — simply vanished during the summarization process, never making it into the searchable memory store. If the details aren’t indexed, they can’t be recalled, no matter how good the retrieval algorithm or the downstream LLM is.
This experience makes me wonder: is this lack of production-ready, detail-preserving memory a key reason why we haven’t seen truly groundbreaking, deeply personalized B2C AI applications take off yet? We have incredibly powerful LLMs like GPT-4o capable of amazing reasoning if given the right information. But the systems designed to feed them that information consistently over long interactions seem to be lagging. The “memory” part of the equation feels like a critical missing piece.
LLMs are undeniably smart, but achieving the kind of persistent, detailed recall we intuitively expect from “memory” is proving harder than the hype suggests. They aren’t quite as smart (or at least, as reliably recall-capable) as we need them to be… yet.
The search, therefore, must continue. Mem0 is just the first framework I’m putting under the LongMemEval-inspired microscope. I’ll be testing other popular solutions — open-source and commercial alike — in upcoming posts to see if any can handle the nuanced demands of true long-term recall without sacrificing the details.
Got a specific memory framework you’re curious about or think might actually crack this nut? Let me know in the comments below! I’d love to hear your suggestions for the next round of testing.
If you liked this and want more AI, tech, or updates on my AI-powered ebook reader,Nekobun, follow me on X at@CalvinJianbaiKU. I’d love to connect and exchange ideas!
Originally published on Medium.