
記憶的難題:為什麼 LLM 需要幫忙記東西
如果你在做 AI 應用,大概早就發現一件事很煩:LLM 的記憶力超爛。ChatGPT 和 Claude 看起來好像什麼都記得,但其實是因為他們的團隊早就把這個問題解決了。換成你自己在開發?那就得靠自己了。
典型的狀況是這樣:你開始做 AI app,一切順利,直到發現 LLM 除了當下這段對話之外,什麼都記不住。想讓它記住上週講過的事?祝你好運。
有些人會自己硬做:把對話存進資料庫、做檢索系統,或想各種聰明的方式壓縮 context。我也走過這條路——最後你花在管記憶上的時間,比做產品功能還多。問題其實很直白:LLM 只會處理 context window 裡的東西。要管什麼進、什麼出?全是你自己的事。而且相信我,很快就會亂成一團。
登場:Letta——給 LLM 應用用的記憶管理方案
這就是 Letta 登場的時候了(以前叫 MemGPT,名字來自他們的 research paper)。你可以把它想成一套對 LLM 來說真的講得通的記憶管理系統。不用自己煩惱該記什麼、該忘什麼,Letta 會幫你處理。
Letta 用兩種記憶:
- Core memory(核心記憶)——就像電腦的 RAM,放現在馬上需要的重點資訊
- Archival memory(封存記憶)——就像硬碟,其他東西存進向量資料庫,需要時再搜
但 Letta 真正有趣的地方,是它像 agent 一樣運作。它遵循所謂的「agentic loop」:
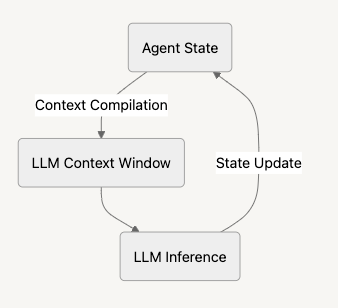
- 從目前狀態出發(它知道、記得什麼)
- 把這些編進 context window(像整理待思考的材料)
- 送給 LLM 決定下一步要做什麼
- 根據 LLM 的決定更新狀態
Letta 很酷的一點是,它會自己決定什麼留在 core memory、什麼移到 archive。context window 快滿了?沒問題——Letta 會自動判斷該留什麼、該先存起來。你完全不用自己寫:
- 算 token
- 決定留或丟
- 建一套找舊對話的系統
- 想怎麼有效壓縮資訊
如果你要做需要長對話、或跨多個聊天 session 還記得住事的 AI app,這超實用。記憶管理交給 Letta,你就專心做產品就好。
Letta 的 Context Window 內部:記憶怎麼被組織

Letta 底層是這樣運作的。你知道 LLM 有個 context window,你把 prompt 塞進去、拿回應?Letta 很聰明地把這個 window(藍色區塊)分成不同區段:
- System Prompt——固定在頂部不動。像 agent 的說明書,告訴它怎麼行為、能用哪些 function(例如需要更新記憶時用
core_memory_replace) - Core Memory——放跟使用者聊天時學到的重要資訊。像是「喔,這位使用者叫 Charles,他剛搬到 SF」。這區太滿時,Letta 會把較舊的內容移到 archival memory——就像把檔案從 RAM 搬到硬碟
- Summary——不會保留整段對話,Letta 會把較舊的聊天摘要起來省空間,跟 ChatGPT 的做法類似
- Chat History——還沒被摘要的近期訊息
依你用的模型,context window 大小會不同,但概念一樣。還有一點很重要:Letta 底層一切都是透過 function call 完成。要存東西以後用?呼叫 archival_memory_insert。要回你訊息?用 send_message。甚至你看到的回覆,底層其實也是 function call,不只是純文字輸出。這讓整體行為一致,也比較好追蹤發生了什麼。
用 Docker 在本機架設
在本機架 Letta 很直接,一條 Docker 指令就搞定:
docker run \
-v ~/.letta/.persist/pgdata:/var/lib/postgresql/data \
-p 8283:8283 \
-e OPENAI_API_KEY="your_openai_api_key" \
letta/letta:latest
這條指令會:
- 掛載 volume 讓 PostgreSQL 資料持久化
- 把 8283 port 開給 Letta 服務
- 設定 OpenAI API key 以存取模型
Letta 也支援多種 LLM 供應商,透過環境變數設定:
ANTHROPIC_API_KEY給 Claude 模型GEMINI_API_KEY給 Google 的 GeminiOLLAMA_BASE_URL給本機 Ollama 模型VLLM_API_BASE給 vLLM 部署
跑起來之後,你可以用幾種方式跟 Letta 互動:
- 直接對服務發 HTTP 請求
- 官方 Python 或 Node.js SDK
- ADE(Agent Development Environment)在 app.letta.com——網頁版 playground,方便試不同設定
 舊版 ADE vs 新版 ADE
舊版 ADE vs 新版 ADE
注意:Letta 可以在本機跑,但 ADE 介面現在只剩雲端版(0.5.0 起)。這跟 Darwin/macOS 的模式類似:核心技術開源,商業介面另外提供。
把 Letta 部署到 Railway
最快的方式是用 官方 template:
- 在 template 頁面點「Deploy Now」
- Railway 會自動用正確的 Dockerfile 和設定
- 在環境變數加上你的
OPENAI_API_KEY
注意:這個 template 連結含我的 referral code。如果你透過這個連結成為 Railway 付費用戶,我會拿到 $5 額度。不想用的話可以拿掉 referral code。
我這裡用 Railway 是因為它比較順手,但 Letta 本質上就是 Docker image,任何能跑 container 的地方都能部署:
- 其他 serverless 平台(Render、Fly.io 等)
- 傳統 VPS
- Kubernetes cluster
- 你自己的基礎建設
選哪個部署方式,看你現有環境和偏好。template 只是用 Railway 時的方便起點。
Railway 內建 PostgreSQL 的問題
在 Railway 部署 Letta 時,你會遇到一個問題:很難直接存取內建的 PostgreSQL。Docker image 沒開 5432 port(雲端部署常見的安全做法),所以你也連不進去。
Railway 有提供 TCP proxy 應付這種情況,但連線時會出錯:
failed: received invalid response to SSL negotiation: H
這很可能是 Railway proxy 設成 HTTP 模式造成的。
一開始看起來像大坑。Letta 文件建議用內建資料庫,也警告外部資料庫可能要 migration 工具如 alembic,或手動 migration。
不過問了 Discord 社群之後,發現用外部資料庫其實很簡單。你只要:
- 架好外部 PostgreSQL
- 設定環境變數
LETTA_PG_URI為你的連線字串
Docker image 會自動處理所有 migration,不用手動介入。
用 Supabase 架設外部 PostgreSQL
把 Supabase 當 Letta 的外部資料庫,需要幾個步驟:
- 在 Supabase 建立新專案
- 在 Supabase SQL editor 執行這段 SQL 啟用 vector 支援:
create extension vector;
這是必要的,因為 Letta 用向量搜尋做記憶檢索,PostgreSQL 需要 vector extension 才支援這種資料型別。
- 取得連線字串:
- Project Settings → Database
- 複製「Connection pooling」底下的連線字串
- 把
[YOUR-PASSWORD]換成你的資料庫密碼
- 回到 Railway,加上環境變數:
LETTA_PG_URI=postgresql://<username>:<password>@<postresql_uri>:5432/postgres
就這樣!啟用 vector extension 之後,Letta 第一次連線時會自動處理其他設定。順利的話,Supabase tables 區塊會看到類似這樣的畫面。
最後幾點
關於 Letta,有幾件事要注意:
- 專案還在積極開發,變動很頻繁:
- Python SDK 從
letta改成letta_client - 他們的 Deeplearning.ai 課程還在用舊版 SDK
- 內部結構如 table schema 可能會變(例如 recall memory 跟 archival memory 合併,如果我記錯請糾正)
- Core tools 從 8 個減到 6 個
- 核心開源,但部分元件走向商業化:
- 本機 ADE 不再支援
- 開發介面得用 app.letta.com
- 還有 Letta Cloud 會幫你處理部署和基礎建設,但還沒公開(可在 https://forms.letta.com/early-access 排 waitlist)
- 上線考量:
- MemGPT/Letta 大概才一年左右
- agent/context/記憶管理這套做法還在實驗階段
- 雖然有潛力,但正式環境的案例可能還不多(或根本沒有)
- 要上 production 請自負風險
- 模型支援不一:
- 目前只有 OpenAI 和 Claude 支援 streaming
- Gemini 等其他模型會關掉 streaming
- 選 LLM 時要記得這點
我才剛開始摸索這個框架,算不上專家。但他們的 Discord 很活躍、也很願意幫忙。遇到問題或想問什麼,那裡是找社群和開發團隊最好的地方。
這個專案在解決 LLM 記憶管理這件事上很有希望,但要心理準備會一直變,上 production 前也要想清楚。記得盯他們的 Discord 和 GitHub 追最新動態。如果你喜歡這篇,想多看 AI、技術,或我 AI 電子書閱讀器 Nekobun 的更新,歡迎在 X 追蹤 @CalvinJianbaiKU。很想跟你交流想法!
原文發表於 Medium。