我花了三個月才「vibe code」出一個簡單的番茄鐘 app
5.265 分鐘閱讀👏 17
- vibe coding
- pomodoro technique
我的導師靠三份兼職和窮到骨子裡的日子撐過來,靠的就是一個簡單工具:番茄工作法。對他有效,這些年對我也有效。
02 / 筆記
關於設計系統、AI 介面,以及把網頁產品打磨到位的隨筆、筆記與開發日誌。
我的導師靠三份兼職和窮到骨子裡的日子撐過來,靠的就是一個簡單工具:番茄工作法。對他有效,這些年對我也有效。
搜尋從 Yahoo! 時代就在了,對多數人來說感覺像「已經解決」。打幾個字、按 Enter,就會出一份「夠用」的清單。
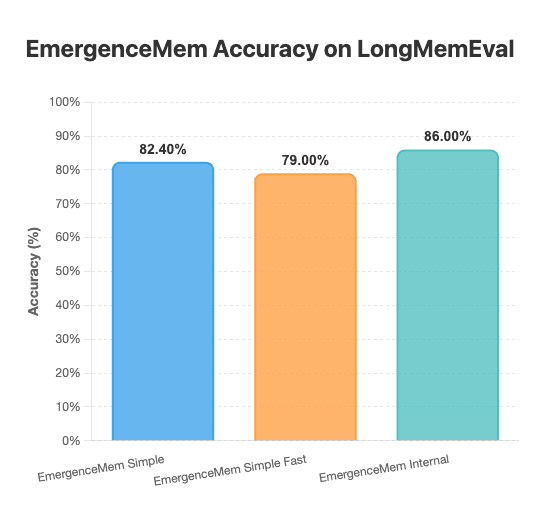
我在 blog 上講過很多次 LongMemEval 資料集。如果你沒深陷 agent memory 這圈,可能沒聽過。它是 ICLR 2025 的 poster paper,為 agent 記憶設了新標準。
如果你最近有在盯 AI,大概注意到一個大轉變。模型不再只是答問題或生漂亮文字——大家開始期待它記得互動、回想偏好,對話要真的像為你客製。
註:本文於 2025 年 9 月 2 日更新,納入 Letta 創辦人 Sarah 的澄清。原版把 Letta 歸類為進階 RAG 的一種;Sarah 澄清 Letta 主要聚焦 context re-writing,可與任何 RAG provider 搭配,本身不是 RAG provider。
大型語言模型(LLM)的革命毋庸置疑,但它們無狀態的本質仍是重大障礙。就像《海底總動員》裡的 Dory,常常忘記先前互動的 context,難以真正個人化、長期對話或任務。
你一定看過這種 hype:GPT-4o 有 128k token!Claude 3 能啃完整本小說!聽起來 AI 記憶已經破解,可以收工了?
前幾天 YouTube 硬把這支影片推到我面前:
如果你在做 AI 應用,大概早就發現一件事很煩:LLM 的記憶力超爛。ChatGPT 和 Claude 看起來好像什麼都記得,但其實是因為他們的團隊早就把這個問題解決了。換成你自己在開發?那就得靠自己了。