我在 blog 上講過很多次 LongMemEval 資料集。如果你沒深陷 agent memory 這圈,可能沒聽過。它是 ICLR 2025 的 poster paper,為 agent 記憶設了新標準。我們從 Meta 的 Beyond Goldfish Memory 和 MemGPT 這類早期里程碑走很長了,但那是另一天的故事。
簡單說,LongMemEval 是 benchmark 對話式 agent 記憶的新 gold standard。我以為 Zep/Graphiti 是明顯領先,直到我在前一篇 The AI Memory Challenge, Part 1 看到 Emergence AI Principal AI Research Scientist Marc 的留言。他邀我看他們的 blog:SOTA on LongMemEval with RAG,他們,嗯,把 Zep 甩很遠。🤯
他們怎麼做到的
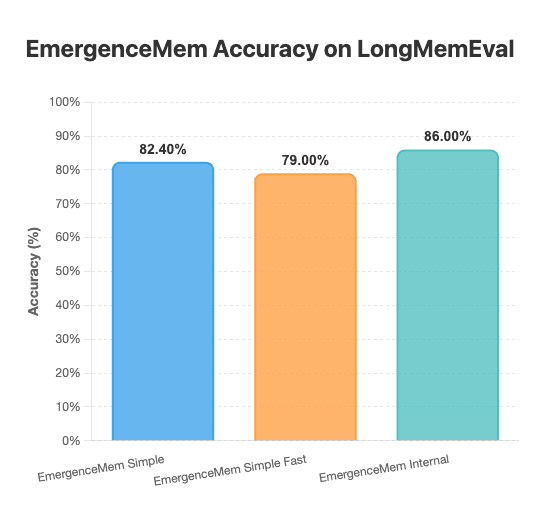
在他們的文章裡,Emergence AI 詳述三種創紀錄的做法:
- EmergenceMem Simple — 82.40%
- EmergenceMem Simple Fast — 79.00%
- EmergenceMem Internal — 86.00%
以下是兩種公開討論方法的 breakdown:
EmergenceMem Simple 很聰明。不是檢索單一對話 turn,而是檢索整段對話。一個 session 的 relevance score 看 rerank 後 top 搜尋結果裡有多少 turn 來自它。例如若最高排名的 turn 多半來自 Session 37,就把整個 Session 37 拉進 LLM context。
EmergenceMem Simple Fast 用兩次 LLM call:
- 先做簡單搜尋,從對話中檢索相關 turn。
- 把問題和檢索到的 turn 組成 prompt,再 call LLM 依問題萃取關鍵事件和事實。
- 萃取的摘要給最終 LLM 生成答案。
他們在另一篇很棒的文章 State of the Art Results in Agentic Memory 對 Internal 版有更多 insight,對這題有興趣必讀。
這篇我想聚焦 EmergenceMem Simple Fast,因為他們好心 [open-sourced it],誰都能跑、驗證結果。
預算夠嗎?用 GPT-4o Mini 測試
Emergence AI 公布的結果用 GPT-4o 這類強模型,對 enterprise 聚焦很合理。我的工作偏向 consumer app,成本是關鍵因素。
如我在 SLMs as the New Memory Core 寫過,AI app 生態被兩大問題卡住:不完整的 AI Tool Layer 和 貴到離譜的 token。foundation models 的高成本造成我說的 LLM-margin squeeze,讓開發者很難做可持續應用。社群要做出下一個 killer app,需要的不只是強,還要買得起。
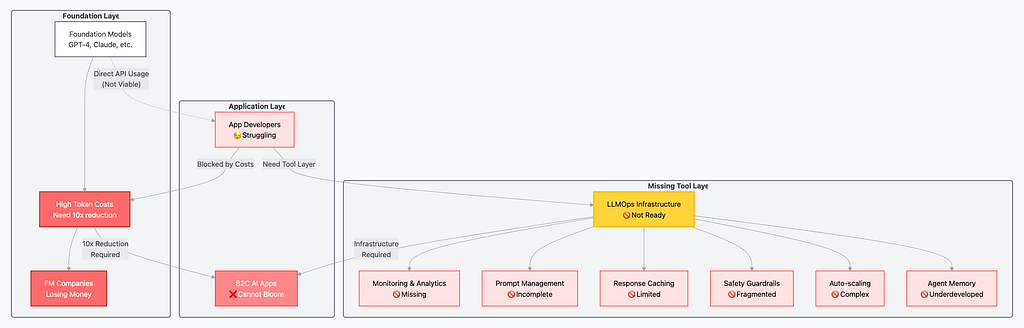 LLM-margin squeeze
LLM-margin squeeze
看到 Emergence AI 開源程式碼,我第一個問題:GPT-4o mini 能 work 嗎?
答案是響亮的 yes。
我愛他們 demo 的簡潔——基本上就是一個 main.py。上手超輕鬆:
- Clone repo。
- 跑 pip install -r requirements.txt。
- 加上 OpenAI API key,模型設 gpt-4o-mini。
- 跑 python main.py。
第一次跑結果很棒。腳本跟 GPT-4o mini 配合漂亮,準確率 71.2%。這結果很驚人,因為跟 Zep 用更強更貴的 GPT-4o 拿到的分數一模一樣!
在家試的話小心:盯著 API 帳單。跑完整 evaluation 不是免費的。
- GPT-4o mini: ~$1.50
- GPT-4o: ~$30.00
如果你只想知道現在 SOTA 是誰,答案有了。但我的工作是看解法是否 robust、可泛化,不是只在特定 dataset 上一次性成功。想知道它真正表現如何,繼續看。
小繞路:讓 Benchmark 更可靠
往下挖之前,得談 evaluation。在 AI Engineering 這本書裡,Chip Huyen 討論用 AI as a Judge 如何成為大趨勢。對評估複雜語言任務有用,但這方法可能不一致、昂貴,而且有點 tautological。
現代模型 structured output 做得很好,我長期倡議用選擇題(MCQ)。10 選格式讓 evaluation 客觀可靠。為此我做了 LongMemEval 的 10 選版本,在 這裡。用 EmergenceMem Simple Fast + GPT-4o mini 測這版,效能 nice bump 到 76.8%。
為了看解法更 broadly 的表現,我也對另外兩個熱門對話 dataset 的 MCQ 版跑測:Multi-Session Chat (MSC) 和 LoCoMo。結果如下:
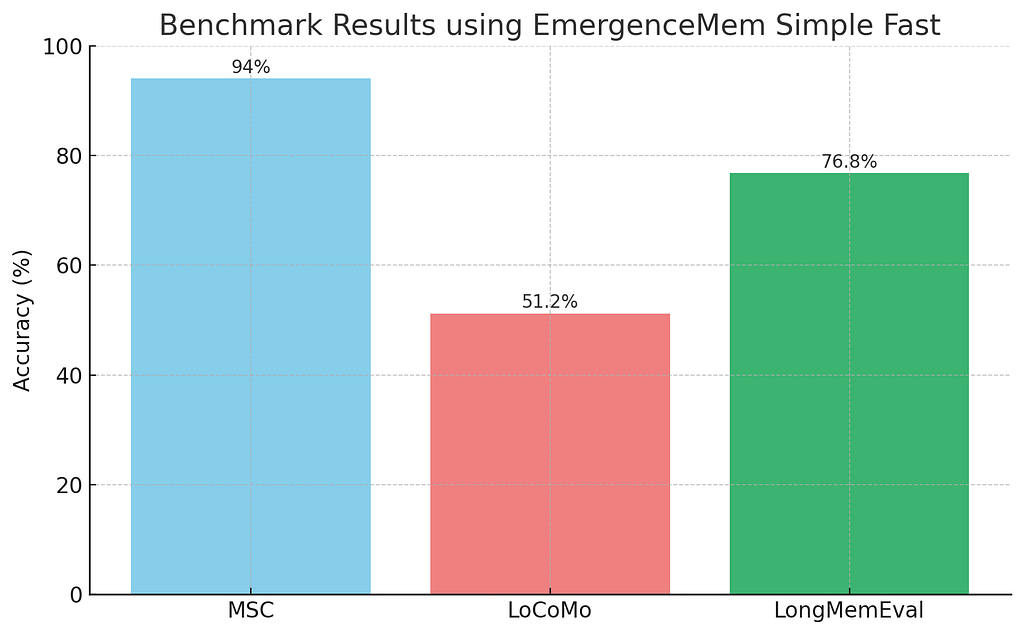 EmergenceMem Simple Fast on MSC, LoCoMo, LongMemEval
EmergenceMem Simple Fast on MSC, LoCoMo, LongMemEval
MSC 高分不意外——dataset 相對簡單。LoCoMo 的分數卻是 huge red flag。
LoCoMo benchmark 不是第一次引人側目。Zep 創辦人在 Lies, Damn Lies, & Statistics 這篇 famously 點名 Mem0,質疑他們在該 dataset 上的分數。
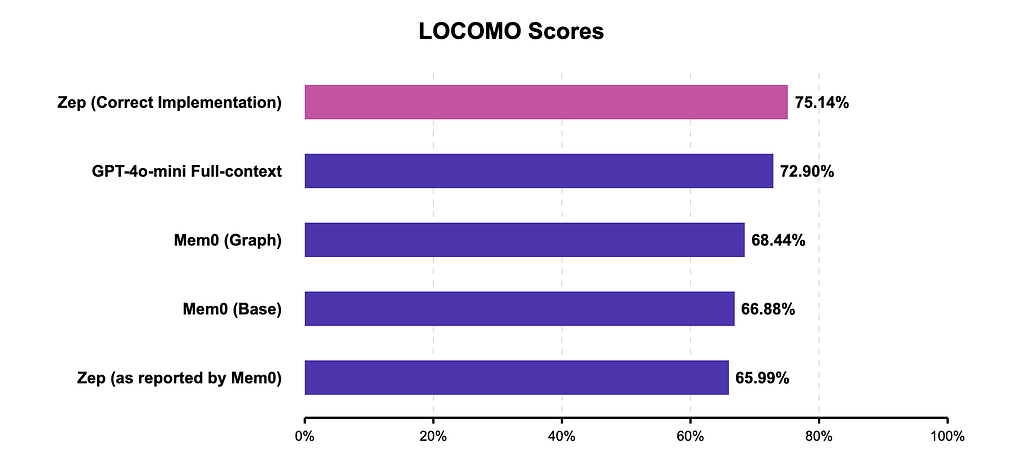 Zep vs. Mem0 on LoCoMo
Zep vs. Mem0 on LoCoMo
這帶出一個 critical puzzle。LongMemEval 普遍被認為比 LoCoMo 難很多。那為什麼 Emergence AI 解法在 supposedly 較簡單的 dataset 上表現差這麼多?
元兇:寫死的 K
要理解奇怪的 LoCoMo 結果,我得挖程式碼。調查聚焦任何 RAG 系統兩個最常見元兇:chunking 和 Top-k。
第一個 chunking 定義資料單元大小。第二個 Top-k 決定檢索多少單元來答 query。根本問題是這些參數沒有 universal 設定。每個 dataset 都不同。
- 有些文件資訊密度高;有些重複。
- 有些問題要 broad context;有些只要一個特定事實。
對一個 use case 有效的固定 chunk size 和 k 值,對另一個幾乎肯定 suboptimal。
Emergence AI 程式碼揭露什麼?做法 refreshingly 簡單。沒有 explicit chunking,每個對話 turn 當 natural data unit。K 值呢?寫死了。
他們對一切設 k=42。
我懂邏輯。turn 是自然的對話單元,42 當然是 life, the universe, and everything 的終極答案。他們似乎把精力放在核心架構挑戰,而不是陷在 hyperparameter tuning。
但這 fixed-k 做法幾乎肯定是 LoCoMo 表現 stumble 的原因。這正是 open-source 社群能發光的地方。我的目標不是找碴,而是看能不能在他們 fantastic 的工作上再疊一層。
超越魔法數字:Adaptive-k 做法
為了解決「fixed k」問題,我開發了更 dynamic、adaptive 的做法。三步驟:
- 設 Token Budget,不是 Chunk Count。 不是檢索固定 k 個 chunk,我先檢索一大批候選,再對最終 context 的總 token 數設 hard limit(例如 8192)。這讓流程獨立於 chunking 策略。 2. 用 MMR 確保多樣性。 我對初始結果套用 Maximal Marginal Relevance (MMR) 演算法。這很關鍵:它 re-rank 文件,打造 balanced context,優先選對 query 高度相關、彼此又 diverse 的項目。這步是避免 redundant 資訊的 key。 3. 用 Top-p 做 Adaptive 選擇。 最後,不用固定 Top-p,我用 Top-p (Nucleus) selection。它 adaptively 選 cumulative relevance score 超過某機率門檻 p 的最相關文件。這更聰明,因為檢索數量——我們的「adaptive k」——會隨每個 query 動態變。
視覺上流程大概像這樣:
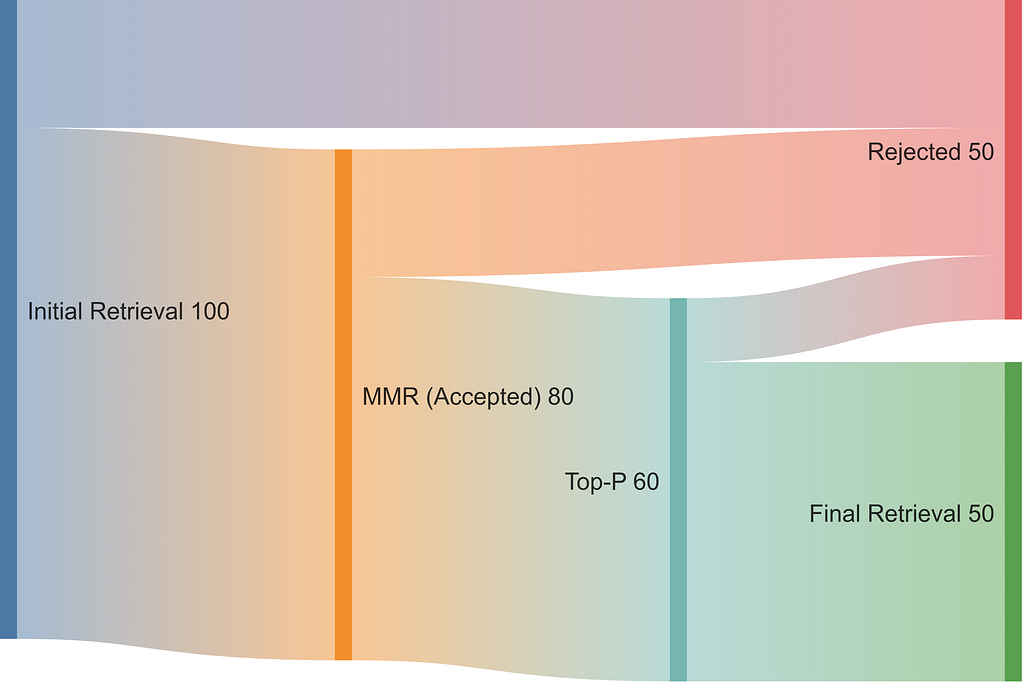 MMR + Top-p
MMR + Top-p
當然這做法也有自己的旋鈕要 tune——namely MMR diversity 參數 λ 和 Top-P 門檻 p。不過這些參數控制的是 dynamic 流程,讓 retrieval size 依需求伸縮,而不是鎖死在一個數字。
結果自己說話:
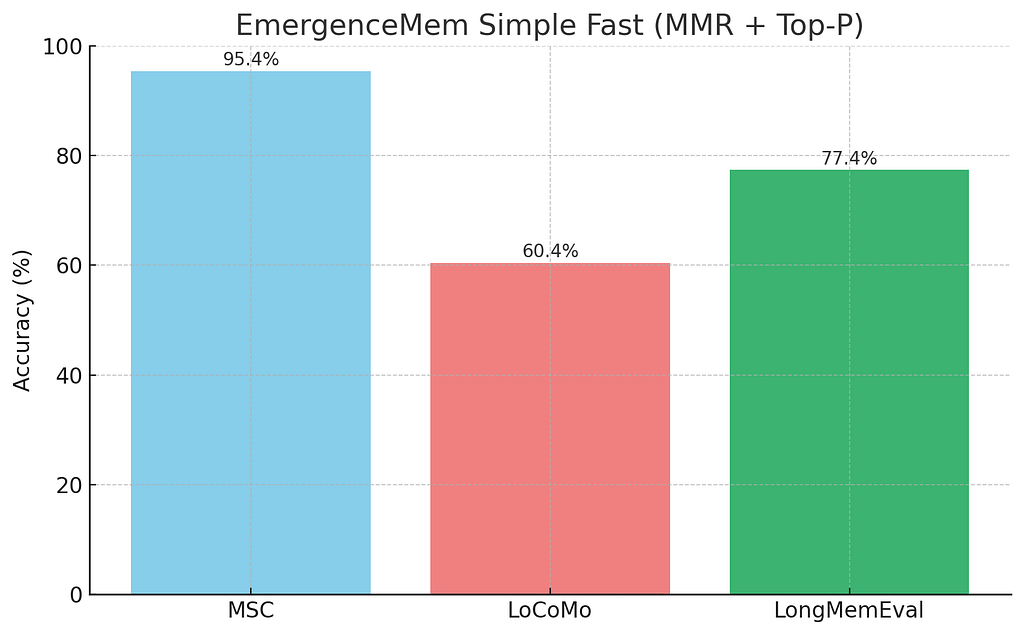 EmergenceMeme Simple Fast (MMR + Top-p) on MSC, LoCoMo, and LongMemEval
EmergenceMeme Simple Fast (MMR + Top-p) on MSC, LoCoMo, and LongMemEval
如你所見,三個 benchmark 都提升,problematic 的 LoCoMo 分數現在健康多了。最好的是?換新 dataset 不用再煩惱選「對的」k。系統會 adapt。
效能 bump 當然有成本。平均檢索數從固定 k=42 變成 dynamic 平均 k=62.5。這讓 GPT-4o mini 跑完整 evaluation 的成本升到 $1.99——漲 42%。我猜那數字真的是一切的答案。😉
再仔細看 retrieval stats,還有很大改善空間:
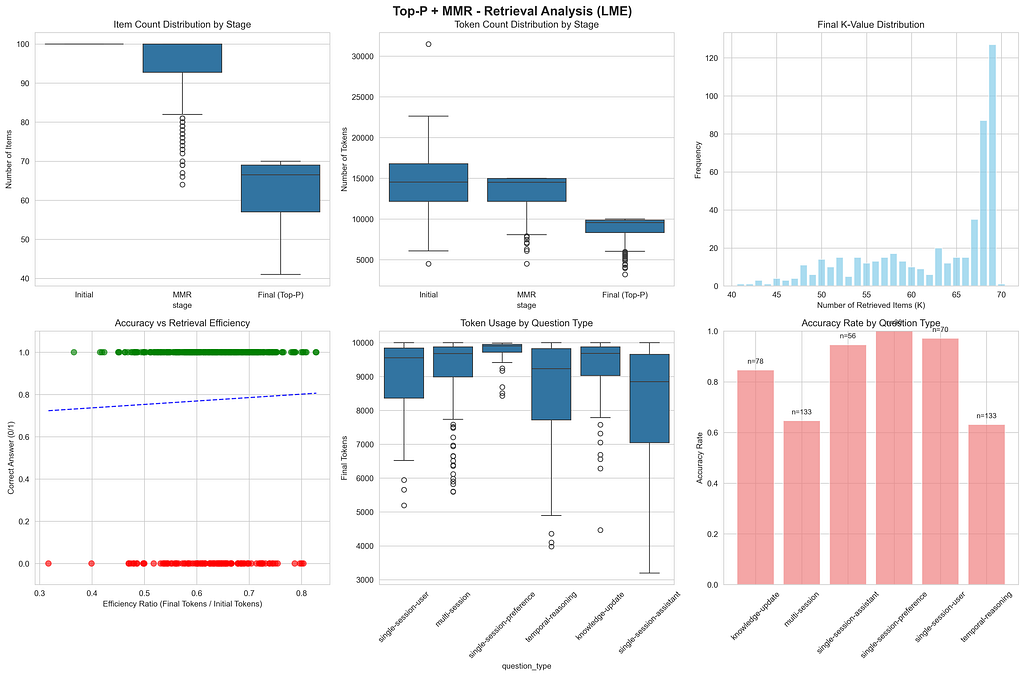 Retrieval Analysis (LongMemEval)
Retrieval Analysis (LongMemEval)
雖然 adaptive k 會變,分布 skew 偏高,mode(最常出現的值)大概在 68。但 quick regression 顯示單純多用 token 跟準確率沒有強 correlation。這告訴我流程還能更高效——完美留給未來文章!
結論
這趟旅程起點很簡單:理解 Emergence AI 在 LongMemEval 的新 SOTA 結果。他們的工作是 agent memory 的巨大前進,但 LoCoMo benchmark 上 surprising 的 performance dip 指向一個小但重要的細節:寫死的 retrieval limit k=42。
這實驗顯示我們能在他們 impress 的基礎上再建。把 fixed k 換成用 MMR 和 Top-p 的 dynamic adaptive 做法,我們看到 clear win。三個 benchmark 都顯著提升,系統也更 robust。不過雖然 adaptive 方法修復了 LoCoMo 的 initial performance drop,最終分數仍低於 Zep 等競品報告的 SOTA。
這個 lingering gap,即使有更 flexible 的 retrieval 演算法,強烈暗示瓶頸已從演算法移到 data representation。我的 gut feeling 是 LoCoMo dataset 獨特結構是 key。不像標準 user-assistant 聊天,它是兩個 distinct 人物(例如 Caroline 和 Melanie)之間的對話。為了塞進 conventional 格式,我 preprocess 時把 speaker 名字直接嵌進 content,像這樣:
[
{
"role": "user",
"content": "[CAROLINE]: Hey Mel! Good to see you! How have you been?"
},
{
"role": "assistant",
"content": "[MELANIE]: Hey Caroline! Good to see you! I'm swamped with the kids & work. What's up with you? Anything new?"
}
]
這做法雖然 functional,可能會 confuse 不是專為 multi-speaker turn-taking 設計的 retrieval 系統。要在 LoCoMo 這類 dataset 上關上最後缺口,很可能需要更 nuanced 的 data preparation 策略。
這 highlight 即使有 flexible 演算法,data representation 仍是 key。當然這 flexibility 不是免費午餐——adaptive 方法提高了平均檢索數,token 成本也跟著漲。
Ultimately,從 fixed k=42 到 adaptive k 的旅程 underscore 一個 crucial 原則:我們應偏好 dynamic、context-aware 元件,而不是 static、「魔法數字」設定。這種 adaptability 是打造不只強大、而且 reliable、efficient 解法的 key。
我相信這是 promising 方向,還有很多可探索——從優化 cost-performance balance 到為複雜對話開發更好的 data 策略。我已把含這些修改的程式碼開源,想實驗的歡迎來玩。
Fork 在這裡:Emergence Simple Fast (Adaptive-K Fork)
你的想法?你也遇過 fixed retrieval 參數或 multi-speaker dataset 的類似挑戰嗎?留言跟我說!
原文發表於 Medium。