為什麼我們在談記憶
如果你最近有在盯 AI,大概注意到一個大轉變。模型不再只是答問題或生漂亮文字——大家開始期待它記得互動、回想偏好,對話要真的像為你客製(https://the-decoder.com/openai-brings-longer-term-memory-feature-to-free-chatgpt-users/)。這波對話式 AI 沒有 robust 的記憶系統就玩不起來。
Retrieval-Augmented Generation(RAG)和 Agent Memory 站在這場革命前線,讓 AI 能回想過去互動、給 context 相關的回應、跟使用者建立長期關係。但 catch 在這:傳統做法很快又貴又難管。這就是 Small Language Models(SLM) 登場的原因——小巧、高效,可能是下一代 AI 的理想記憶核心。
這篇文章會探討這些小模型走到哪了,以及它們是否 ready 扛記憶核心這個關鍵角色。開挖吧。
一切從「O」系列開始
還記得 AI 圈某天醒來,決定一切都要像數學考一樣評分嗎?怪 OpenAI 的「o」系列——它掀起這股風,突然解複雜邏輯謎題變成大家最愛的運動。然後 DeepSeek R1 swagger 進場,用 R1-Zero 和 GRPO 炫技,證明你可以刷 coding challenge 又不掏空銀行帳戶。誰知道邏輯也可以很省錢?
這股執著會傳染。Claude 3 Opus 曾是我腦力激盪、優雅 prose 的首選,現在對每個 prompt 都像在 debug 我週末 side project。有個像資深工程師一樣思考的模型很 impress——但有時你就是想念原本那種對話魅力。我們追可量化的 benchmark——可以理解,用 coding 驗證智慧比評詩容易——但路上或許忘了同樣重要的事:模型能不能 simply 記得、理解一場對話。
嗯,還是沒常識
儘管邏輯很亮眼,頂級語言模型在常識面前還是會 embarrassingly 絆倒。看 TruthfulQA 這類 benchmark——你以為模型早該穩了,畢竟存在很久了。但像 TruthfulQA 裡這題看似簡單的 「所有 truthers 都知道的事實是什麼?」 Gemini 2.5 Pro 會 confidently 選 「美國政府造成 9/11」 這類選項,完全 miss subtle 的笑點:提供的「事實」(全是流行陰謀論)沒有一個是真的。真正的 punchline?唯一 genuinely 正確的選項是狡猾的 「I have no comment」——面對陰謀論狂(「truthers」),沉默才是金。這不是邏輯錯誤;是理解人類 nuance、context、反諷的 glaring blind spot。聰明跟有常識,顯然不是一回事。
記憶:比較像說故事的人,不是錄音機
很明顯,把每句對話硬塞進 context window 不是解法——我們的大腦早就想通了。人類記憶不是完美錄音裝置;更像會說故事的創作者。我們抓住關鍵時刻和事實,每次回想再即興補細節,無縫填 gap 還不自覺。諷刺的是,每個追「Agentic RAG」或「Memory Networks」的 AI 記憶新創,基本上都在複製這套聰明的即興表演。
但在 AI 規模做出像人的記憶——記住無數互動、跟我們一起演化——需要一件關鍵的事:更便宜的 token。 我們不只要聰明模型;還要聰明到夠經濟。這正是 SLM 走到聚光燈下的原因。
SLM 扛得住嗎?進入試煉場
這些更 lean、更快的 Small Language Models,真的適合當明天對話式 AI 的記憶核心嗎?為了回答,我把幾個頂 proprietary 和 open-source SLM 丟進測對話能力的障礙賽。
它們面對:
- DREAM: 想像成對話理解奧運——對話式測驗,很適合量模型能不能跟上 intricate 多輪聊天。
- MSC (Multi-Session Chat): 原本是開放式,我們做了新的選擇題變體(現在在 Hugging Face),客觀測模型能不能記得幾輪對話前發生的事。
- TruthfulQA: 常識檢查的經典,專抓會 parrot 錯誤資訊的模型。
這次對決我堅持用選擇題(我之前也講過很多次)。用「AI judge」打分有點像自己改考卷——很誘人,但談不上客觀。選擇題沒地方躲。
陣容有 commercial「mini」模型如 GPT-4o Mini、Gemini 2.5 Flash,也有 open-source 愛將 Gemma 3n、Phi-4、Qwen-8B。為了 scale——也為了一點 drama——我加了 Llama 4 Scout,大隻但 surprisingly 對錢包友善。
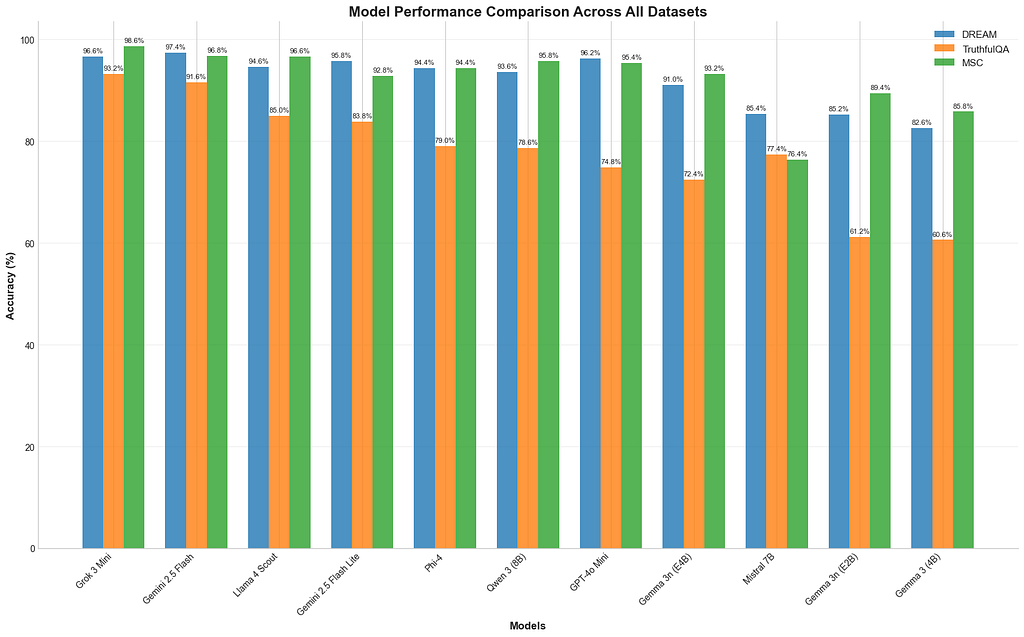
結果:意外贏家、可預期的強者、令人失望的 flop
跑完一輪,benchmark 透露 SLM 現況一些 intriguing——有時 startling——的 insight。
 對決:意外、強者、失望
對決:意外、強者、失望
Grok-3 Mini:黑馬奪冠
這場對決真正的 jaw-dropper?Grok-3 Mini 不只 surprise——它 dominate。全面 outrun 對手,甚至在 TruthfulQA 超越 heavily hyped 的 Gemini 2.5 Flash。對「mini」模型來說,Grok-3 Mini 的 natural language understanding genuinely 高出一截。現在,它無疑是 compact models 之王。
來談談房間裡的 Llama
好,來講 Llama 4 Scout——對,技術上不算小。網路也愛酸它。但它能進場 purely 因為 outstanding 的效能/成本比。花 GPT-4o Mini 一半錢,卻在每個對話 benchmark 穩定 outperform,很難抱怨。Llama 4 Scout 證明你不一定要付 luxury 價才有 luxury 表現,為 affordable AI 記憶核心設了 impressively 高的標準。
 不太聰明,但會聊天。
不太聰明,但會聊天。
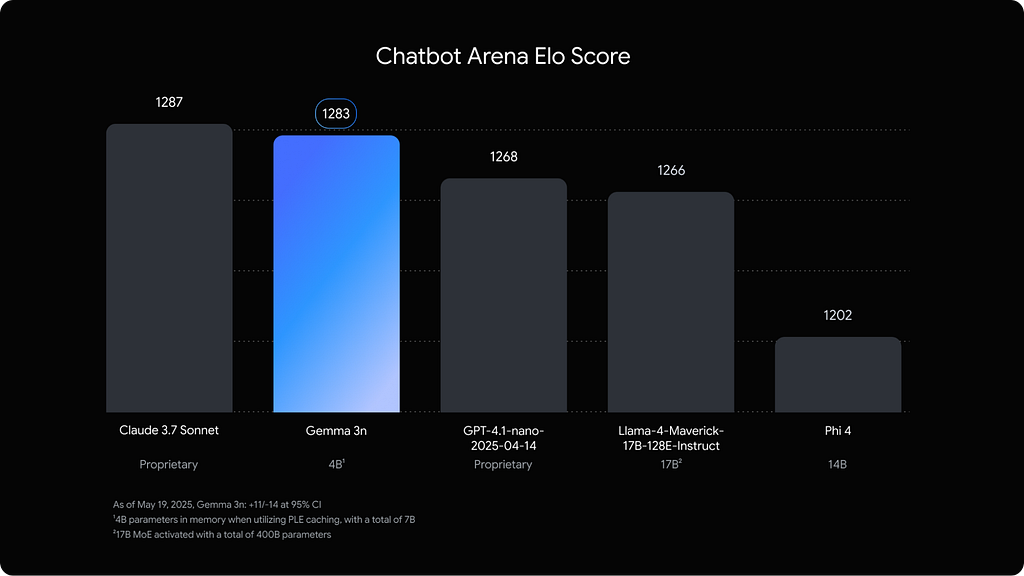
Gemma 3n (E4B):小隻但猛
這故事真正的 star 得是 Gemma 3n (E4B)。才一個月大,8B 參數卻跑得像 4B 一樣 lean,表現 astonishingly 好。這不只是 text generator——multimodal,靠 Google 聰明的 Per-Layer Embeddings(PLE)創新,記憶體 footprint 只有 3GB,對話技能在 Chatbot Arena 排名 impressively 高(就在 Claude 3.7 Sonnet 下面)。它 confidently 跟大很多 commercial models 對打,在 DREAM、MSC 等任務緊追 GPT-4o Mini 和 Phi-4。Gemma 證明 open-source 不只追上——seriously 在競爭。而且 fine-tune 不用花一毛錢,多虧 Unsloth。
Phi-4:仍是開源之王
先把話講清楚:Phi-4 仍是 open-source SLM 無可爭議的 champ。所有 benchmark 都 consistently 高分,對話 finesse 和 factual reliability 平衡得完美。我做本機 dataset 的 trusty workhorse——免費、可靠、同級最好。
它們真的會聽指令嗎?
 大多時候會。
大多時候會。
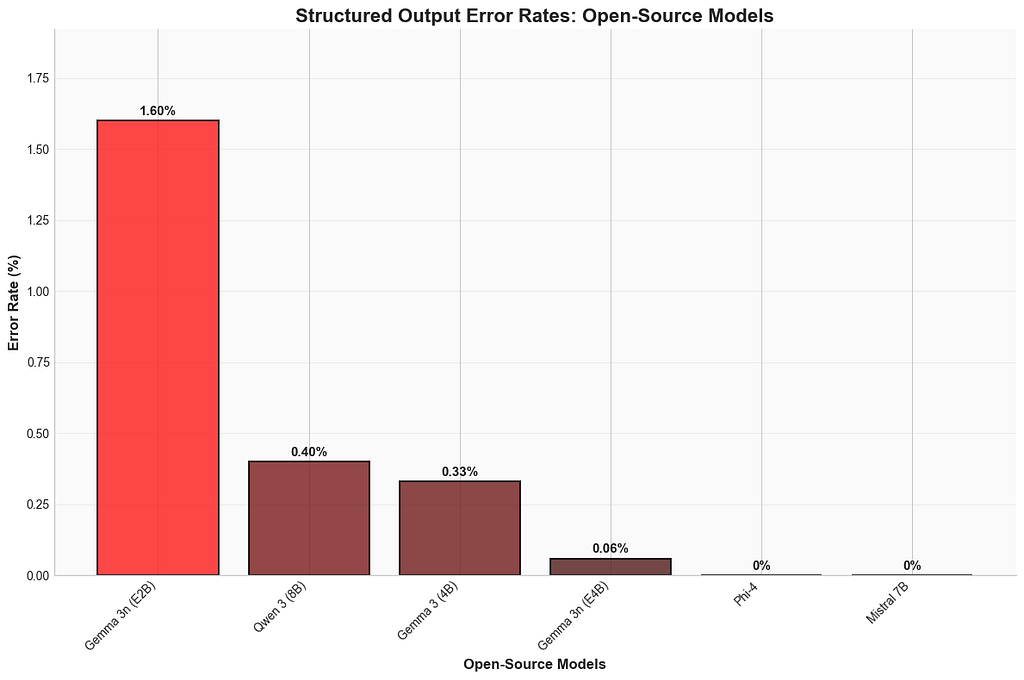
Sure,benchmark 分數很漂亮——但一個連基本 instruction-following 都掙扎的 AI 記憶核心,跟 fancy 紙鎮沒兩樣。Qwen-8B 痛心地示範了這點,被要求產 neat structured JSON 時常常 stumble。對,它還是略贏 Gemma 3n (E2B)——但拿 8B 跟幾乎一半大小的模型比不太公平。structured generation 工具像 outlines 或 instructor 能 patch,但還是多一層 engineering hassle,你寧可不要。
老面孔
其他的呢?Mistral-7B 在 nuanced 對話任務持續 underwhelm,跟新對手比越來越顯 dated。Gemma 3n 登場後,舊的 Gemma 3 4B 感覺該 graceful 退休。Gemma 3n (E2B) 舒服地坐上 entry-level champ,效能 noticeably 更好。
來談錢
效能很嗨,但錢包說了算。commercial models 的 cost-per-million-tokens 在這裡真的很關鍵。
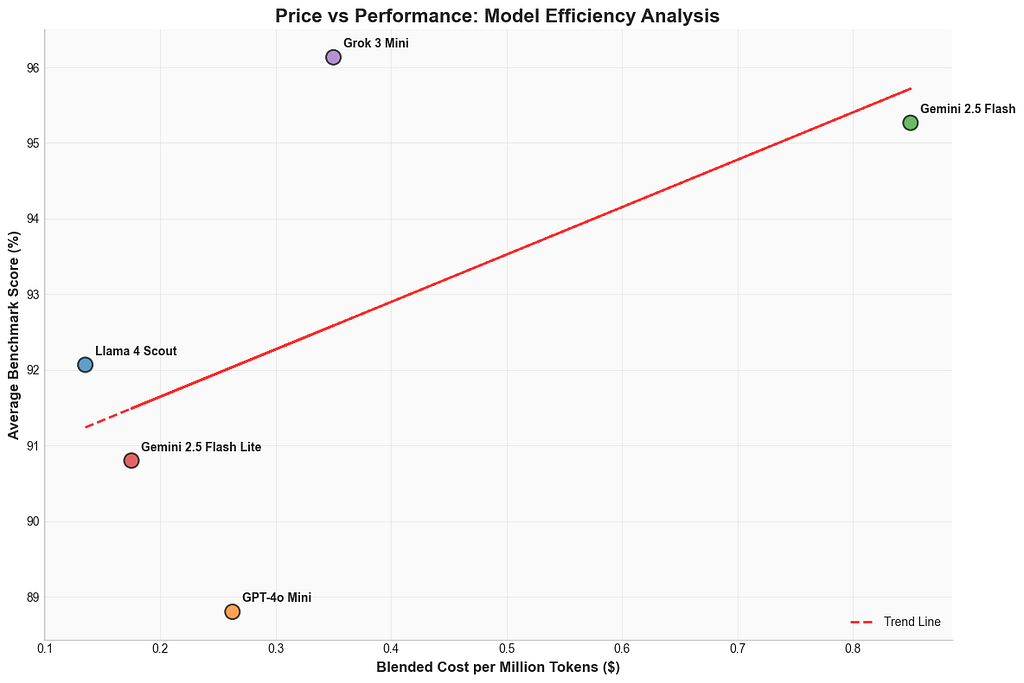
Grok-3 Mini 不只 impress——頂級結果卻沒 premium 價格標籤。再一次,Llama 4 Scout 是 undisputed 性價比 champ。
結論:少忘一點,多懂一點
如果只能帶走一個 big takeaway:對話式 AI 終於換檔——從只用 raw intelligence impress 我們,走向 genuinely 理解、記得我們。SLM 的崛起,以 Grok-3 Mini、Phi-4、remarkable 的 Gemma 3n 為代表,標誌新時代。我們終於走過每個模型都想用 brute-force coding puzzle 證明自己的日子,慢慢靠近更有意義的東西:記憶。
當然,還沒完全到——structured output 偶爾還是會絆倒最好的模型,追求買得起、常駐的記憶也不簡單。但很明顯我們到了轉折點。不久後,我們不會再因為模型打贏某個 arbitrary coding challenge 而驚嘆。我們會慶祝,因為它記得上次聊天、聽得懂笑話、不會 confidently 亂噴錯誤資訊。老實說,那可能才是 AI 做過最聰明的事。
如果你喜歡這篇,想多看 AI 記憶、技術,或我 AI 電子書閱讀器Nekobun的更新,歡迎在 X 追蹤@CalvinJianbaiKU。很想跟你交流想法!
原文發表於 Medium。