
註: 本文於 2025 年 9 月 2 日更新,納入 Letta 創辦人 Sarah 的澄清。原版把 Letta 歸類為進階 RAG 的一種;Sarah 澄清 Letta 主要聚焦 context re-writing,可與任何 RAG provider 搭配,本身不是 RAG provider。延遲相關段落也依她的 insight 更新。
「我們不是 RAG」的 deception
四個月前,AI 新創 Letta 發了「RAG is not Agent Memory」解釋他們做的不是 RAG。省你時間,重點如下:
- Context Pollution: RAG 把太多無關資料塞進 context window,可能傷害 LLM 推理能力。
- Single-Step Process: RAG 只做一次 retrieval 和 generation,對需要更深理解來源的複雜任務不夠。
- Purely Reactive: RAG 只根據跟 immediate prompt 的語意相似度檢索,無法連起 context 相關但語意距離遠的資訊(例如把使用者先前提到的最愛顏色,連到現在聊生日的對話)。
- Letta 的「Agentic RAG」哪裡不同: 他們的多步、agentic RAG 不一樣,解決上面所有問題。
我喜歡這篇文章的一點:它 highlight agent memory 的重要性——多數開發者在 LLM 上疊東西時大概都會撞到。我不喜歡的是其他所有說法。這是錯的方式強調 Agent Memory 重要:攻擊稻草人。
好笑的是,五天前另一個 AI 新創 Zep 發了「Stop Using RAG for Agent Memory」, preach 他們版本的 RAG 多爛、他們不是 RAG。
- No Temporal Awareness: RAG 分不清舊資訊和新資訊,常檢索到過時事實。
- Inability to Understand Causality: 抓不住事件關係,例如負面經驗導致偏好改變。
- Fact Invalidation: RAG 無法有效處理事實不再成立的情況。
- Zep 的「Graph RAG」哪裡不同: 底層用 knowledge graph 的 RAG 解決上面所有問題。
我不必重複為什麼不喜歡這篇。很簡單:
Letta 和 Zep 都是 RAG,卻在假裝不是。
這讓我想起 Peter Thiel 在 Zero to One 說的:
「Monopolists lie to protect themselves. They know that bragging about their great monopoly invites being audited, scrutinized, and attacked….Non-monopolists tell the opposite lie: “we’re in a league of our own.” Entrepreneurs are always biased to understate the scale of competition, but that is the biggest mistake a startup can make.”
別誤會。我喜歡 Letta 在做的事;我之前的文章也講過很多次。我也覺得 Zep 是目前 tackling temporal reasoning 最好的做法。我完全同意 Agent Memory 不是 RAG。問題在這:Agent memory 不是 RAG,但理由跟他們說的完全不一樣。
講對了:RAG 是解法,Memory 是問題
對,就這麼簡單。說一個不是另一個是 category mistake。我不覺得他們是意外犯這個錯。他們的講法像:喔,RAG 太 low-tech,大家都會。才不,我們絕對不是那個。我們厲害多了。 這是我討厭的。
破除迷思:RAG 不是 low-tech 玩具
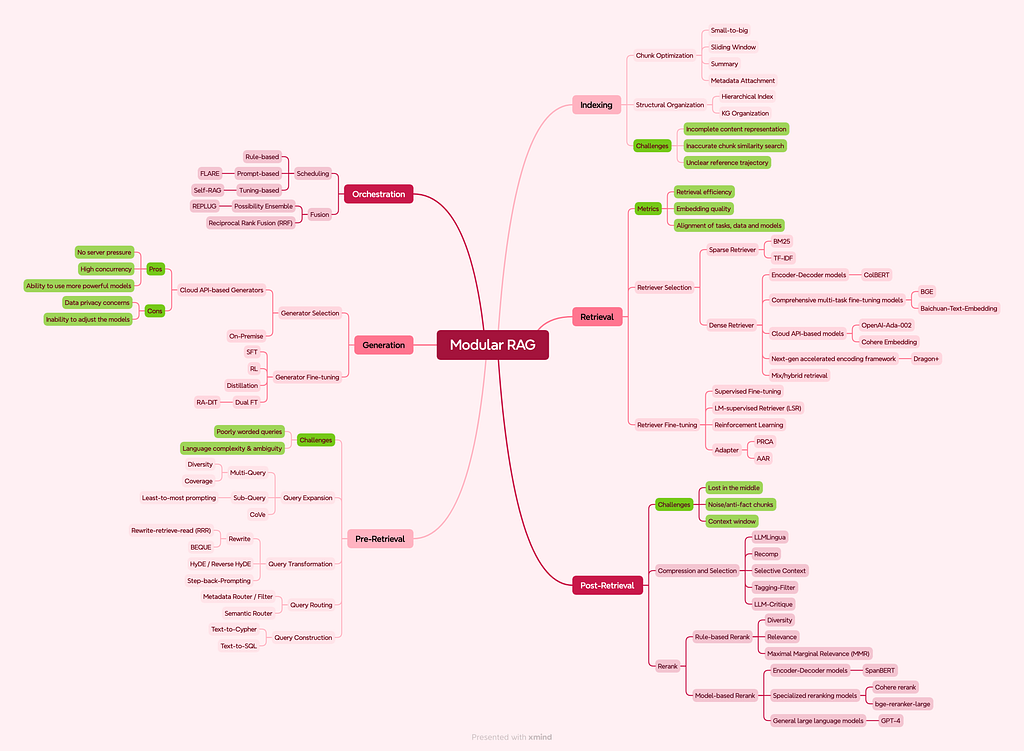 Everything You Need to Know about Modular RAG
Everything You Need to Know about Modular RAG
幾個月前「agentic」這詞還很少人講時我做了這張 mind map(很瘋吧?如今大家覺得理所當然的東西,幾個月前還不存在)。之後肯定能大幅更新,但概念你懂。我們現在叫「Agentic RAG」的,當時 RAG 圈更常叫「Modular RAG」(含 orchestration)。我之前把 Letta 歸在這裡,但他們創辦人澄清他們聚焦 context re-writing(靈感來自 MemGPT 等概念),可連到任何 RAG 工具,而不是 RAG provider。這個區分很重要。Zep 的 Graph RAG 則是 RAG 典範清楚又強力的演進。更廣的論點仍成立:這些進階系統建立在 retrieve、augment、generate 的基本原則上。
AI 記憶版圖:RAG 真正站哪裡
如我說的,說 RAG 不是 AI memory 跟說 RAG 就是 AI memory 一樣錯。在 LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory 這篇 paper 裡,作者把 AI memory 做法分成三類:
- In-Context Learning: 讓 LLM 適應把大量歷史當 long-context 輸入處理。
- Memory Networks: 把可微分記憶模組整合進語言模型。
- RAG: 含 context compression、embeddings、discrete tokens。各種 RAG。
要給 AI 記憶,我們不必只限 RAG。三類裡 Memory Networks 最 sexy,可能是很多 AI unicorn 的未來方向。In-Context Learning 最不 sexy,但誰都能用,很多 use case 也夠用。RAG 在中間,可能是現在最可行的路。所以雖然這些新創聲稱不是,他們其實都走 RAG。研究角度或許不那麼有趣,但要真的 work 需要很多 engineering magic。
如果你對 RAG 不熟,那篇 paper 的作者也用三階段模型統一看 RAG 怎麼運作。
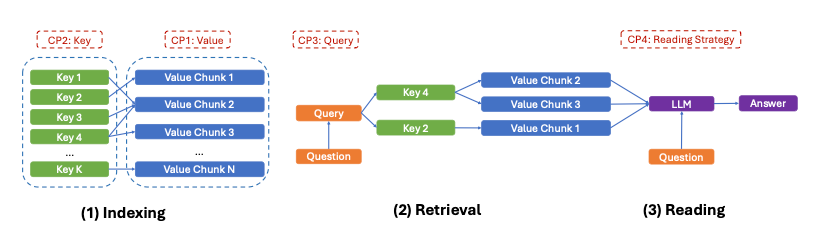
真正的挑戰:Agent Memory 為什麼這麼難?
我認為 RAG 的限制在第一階段:Indexing,或更精確說,第一個 control point——我們怎麼 chunk 文字。chunk 的方式有無限多,沒有唯一正解。而且電腦存文字的方式讓更新值很難。在這個意義上,Knowledge Graph 像是 natural choice。但要真的 work 仍然很難。接下來我會輕點幾個給 AI agent 記憶時的大問題。
學術界的五道關卡
LongMemEval 把問題分成五類:
- Information Extraction (IE): 從大量歷史中 recall 特定資訊。
- Multi-Session Reasoning (MR): 跨多個 session 綜合資訊。
- Knowledge Updates (KU): 動態辨識並更新使用者資訊。
- Temporal Reasoning (TR): 對資訊的時間面向有意識。
- Abstention (ABS): 知道什麼時候該說「我不知道」。
如果不好懂,作者很貼心地給了詳細 illustration 展示每類問題。
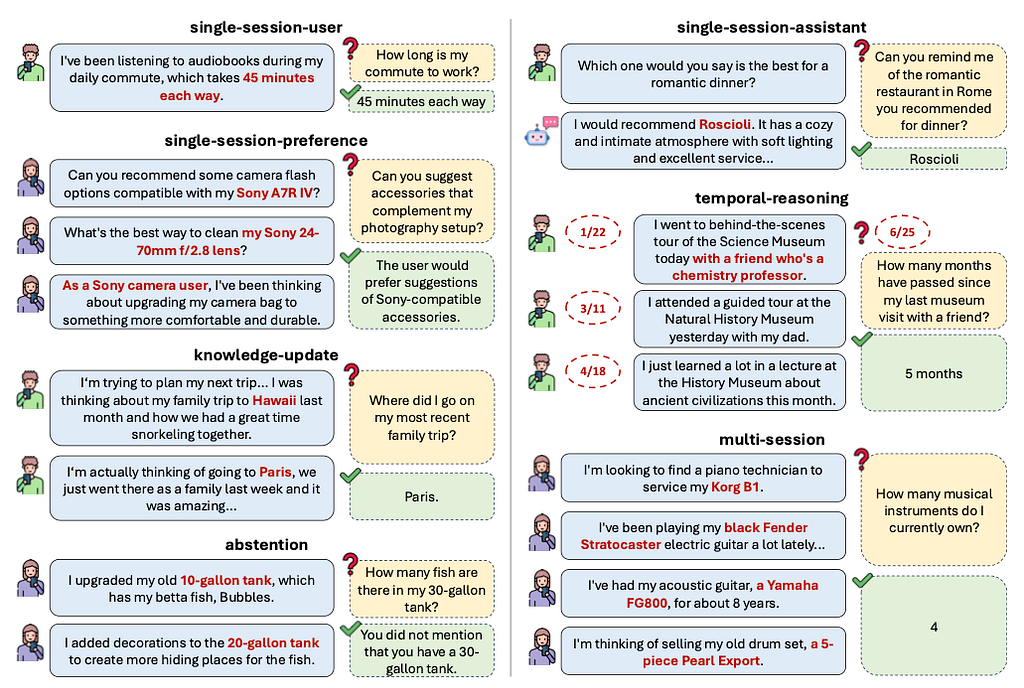 Five Core Long-Term Memory Abilities
Five Core Long-Term Memory Abilities
多數其實很難。做 RAG 時如果沒把這些問題放在心上,你的 RAG 幾乎肯定處理不了。一月 Zep 發了篇 paper 聲稱解了 45.1% temporal reasoning 和 78.2% knowledge update。我別處也講過看法(像行銷 brochure 偽裝成 technical report),但如果結果沒造假,這真是 remarkable achievement。我不覺得 Letta、Mem0 等其他 commercial 競品能接近。
現實世界再加三個頭痛
LongMemEval paper 很 thorough,也給了我們更系統談記憶問題的框架。如果你對記憶問題有興趣,強烈建議讀。
不過 paper 沒涵蓋幾個重要面向:
- Dynamic Information Ingestion
- Latency
- Knowledge Conflict
Dynamic Information Ingestion
如我前面說,我相信 chunking 是我們面對的最大瓶頸,受限於現有儲存技術。你在 Google 或 YouTube 搜,會看到各種 chunking 方法。但都在 non-dynamic setup 討論——也就是文字已經全在手上了,只要想怎麼 chunk。現實世界資料是 real-time 進來的。我們不知道何時來、來多少、還會不會再有。不知道這些,chunking 會很難。
Latency
multi-step、agentic 系統常有人擔心 latency。但 latency 從哪來可能被誤解。例如 Letta 的 Sarah 澄清,像 send_message 這種 tool call 不一定加 latency overhead,因為 LLM API call 本來就要發生。對他們這類系統,更顯著的 latency 可能來自 write-heavy——把狀態 persist 到資料庫做長期記憶。這 highlight 記憶系統的關鍵 trade-off:確保 robust、persistent 記憶可能帶來延遲,不過現代工程像 async client 能大幅緩解。
Knowledge Conflict
假新聞滿天飛的時代,我們人類習慣周遭資訊只有部分為真。好消息是我們的心智能處理。壞消息是熟悉資料庫的工程師習慣資料庫裡存的是「事實」。你會看到 knowledge graph 圈很愛用「fact」這詞。我不介意這詞,但要知道我們不是在存事實。我們存的是某種意義上高度可能為真的信念,全部都可能變。我們的心智就是這樣存。Agent Memory 要像人腦 work,agent 也該存這種東西。
後記:我在記憶這局的 stake
我對 Agent Memory 有興趣,是從做 Nekobun 這個 AI 電子書閱讀器開始。夢想是讓可愛貓角色不只評論文字,還能跟使用者 genuinely insightful 對話——記得過去討論、偏好、共同時刻,打造真正個人化體驗。那種個人化完全仰賴 robust、可靠的記憶系統。找了一圈 solid 解法,發現做 AI app 這塊 crucial 環節還沒到位。我決定 pause 一下,自己研究這題。我會持續在這分享發現,如果你也感興趣,很想跟你連上。
如果你喜歡這篇,想多看 AI 記憶、技術,或我 AI 電子書閱讀器Nekobun的更新,歡迎在 X 追蹤@CalvinJianbaiKU。很想跟你交流想法!
原文發表於 Medium。