
AI 記憶挑戰,第一篇:我們請 Mem0 記住五件事。結果如何?
為什麼長期記憶還是讓人頭痛
你一定看過這種 hype:GPT-4o 有 128k token!Claude 3 能啃完整本小說! 聽起來 AI 記憶已經破解,可以收工了?
才沒有。
更大的 context window 很棒,但單純塞更多 token 不代表模型真的會好好用那些資訊。就像給某人一本超厚講義去考試,他卻從沒翻開。資料再多,如果被忽略,就不算記憶。
大海撈針測試:可愛,但有瑕疵

還記得舊 benchmark 嗎?把一句話(「針」)藏在大量文字(「草堆」)裡,看 AI 找不找得到。簡單、可自動化……但後來發現,它太簡單了。
為什麼?那些「針」常常超突兀。LLM 很會抓明顯 outlier——那句在喊 「嘿,我跟這裡不搭!」 的句子——而不是真的讀完整堆草。 (像 Claude 3 甚至還注意到自己在被測!)
抓 outlier ≠ 真正的記憶
所以 AI 記憶解決了嗎?差遠了。 找到怪句子不是長期 recall;只是華麗的把戲。
真正的記憶意味著:
- 萃取多個事實。
- 跨事實推理。
- 用新資訊更新信念。
- 理解序列並綜合資訊。
大海撈針測不出這些。模型沒有在記憶上變聰明;benchmark 只是變得太 predictable。
登場:LongMemEval(問對問題)
幸好新的 LongMemEval benchmark 來真的了。別只找怪句子。它測反映真實記憶的細膩技能:萃取事實(IE)、連點成線(MR)、更新知識(KU)、追蹤時間(TR)、以及 abstention(ABS)。
它針對常見 AI 失敗,描繪真正長期 recall 的 richer 圖像。與其問「它有沒有找到隨機句子?」,LongMemEval 終於問對問題:
「它有沒有理解任何一點?」
LongMemEval:真正重要的五項任務
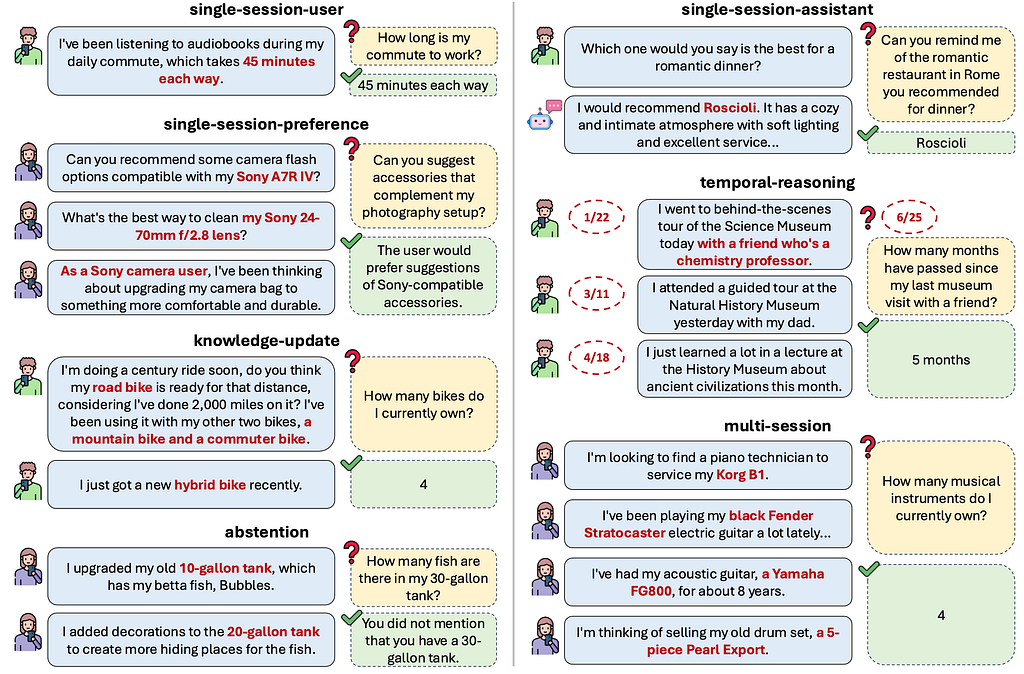
那 LongMemEval 比玩「找怪句子」好在哪?它把長 context 裡的「理解」拆成五個具體挑戰——那種真的會絆倒想 session 接 session 記事的 AI 助理的東西。比較像「有用助理」,比較不像「把戲」。
快速 rundown,附這些測試實際長什麼樣的例子:
- Information Extraction (IE): 事實埋很深時,模型能不能 pinpoint 並抽出特定事實?像在幾小時其他閒聊裡曾提到羅馬餐廳,之後問 「提醒我你推薦羅馬哪家餐廳?」 (答案應該是「Roscioli」,不是 rambling summary)。
- Multi-hop Reasoning (MR): 能不能連起散落在對話裡的點?先提到鍵盤,後來吉他,再很久之後問 「我總共提到擁有幾種樂器?」 AI 得找到所有提及並加總(例如 Korg B1 + Strat + Yamaha + Drums = 4)。
- Knowledge Updating (KU): 事實變了怎麼辦?先說有 3 台腳踏車,後來提到買了新 hybrid 車,再問 「我現在有幾台腳踏車?」 AI 能不能更新知識正確答「4」?還是 cling 舊資訊或搞混?
- Temporal Reasoning (TR): AI grasp 何時發生的事嗎?一月提到跟朋友逛博物館,後來又有其他行程,六月問 「跟朋友那次博物館是多久前?」 能不能依特定事件正確算「5 個月」?
- Abstention (ABS): 知不知道不該答?問到不確定或沒資訊的事,AI 能不能適當拒答而不是瞎掰?例如從沒提過 30 加侖魚缸,卻問「我跟你說過 30 加侖魚缸什麼?」會不會正確說沒紀錄?
看到了吧?這些不只是 retrieval trick。直擊為什麼打造真正有用、長期 AI 助理這麼難的核心:跨時間推理、處理矛盾、看大局而不只是孤立事實。這些才是現有系統常 stumble 的真痛點。
官方 LongMemEval paper 真的 push envelope,用整整 500 輪對話 entry 測模型,模擬超長互動。這就是 LongMemEval 感覺 legit 的原因——proper stress test for AI memory。因為它量的是有意義的東西,我決定用它來測最受歡迎的記憶框架——commercial 和 open-source 都有。這是一系列的起點,第一個上場的是知名的 Mem0。看看它扛不扛得住。
縮小規模貼近現實:5 題迷你 Benchmark
好,完整 LongMemEval 涵蓋五種 distinct 記憶技能,但講真的:有些任務像複雜 temporal reasoning(TR)或 knowledge updating(KU),對今天的 AI 記憶系統來說* brutally* 難。一次測全部像叫幼兒跑馬拉松,尤其考慮 Mem0 免費「Hobby」方案的實務限制(API call 和記憶儲存不是無限)。
所以這次深入測試,我們用 focused mini-benchmark 鎖定 essentials。只 concentrate 兩個 fundamental 領域:
Information Extraction (IE): 系統能不能 simply 取出先前提到的特定事實?測兩種變體:
- IE (Single-Session User): 從過去 user message 取資訊。
- IE (Single-Session Assistant): 從過去 assistant response 取資訊。
Multi-hop Reasoning (MR): 能不能連起散落在對話歷史裡的簡單點?
為什麼只測這些?因為連這些 foundational 技能都可能 surprisingly tricky。得先確認框架能 handle basics,再談 KU、TR、ABS 那種進階記憶體操。
為此我準備了短的模擬對話歷史,並 crafted 一小組 targeted questions(這輪總共 5 題),專門 probe IE 和 MR。
怎麼判分?忘掉複雜 setup。只有 5 題,我們直接肉眼對答案。
- Direct Manual Check: 對 memory-enabled 系統跑問題,手動檢查生成答案是否正確用到儲存資訊。萃取的事實對嗎?有沒有 properly 連點?
- No AI Judge Needed: 完全 bypass 原 LongMemEval paper 用的 AI judge。AI judge 有趣,但加複雜度,也可能引入自己的錯誤或 bias。肉眼檢查少量答案更快、更簡單,在這個規模 arguably 更可靠。
這種 direct 做法給我們 clear、no-fuss 訊號:記憶系統有沒有正確處理這些 fundamental 任務。來看 Mem0 在這種 focused、manual scrutiny 下表現如何。
測 Mem0:架設難題、匯入策略與 Commercial 路線
好,來講重點:Mem0 在我們 focused mini-benchmark 上到底表現如何?
首先:你可能好奇為什麼我選 Mem0 的commercial API,他們也有 open-source。簡單答案:open-source 路線根本走不通。 要跑起來得跟 Neo4j、冷門 plugin、稀疏文件搏鬥,最後還撞上 cryptic errors(ERROR:root:Error in new_memories_with_actions)和 vague 解釋(「LLM hallucination」)。經歷那一切之後,commercial API 像是唯一務實的路。
準備「草堆」:把記憶匯入 Mem0
跑 benchmark 問題前,得把模擬對話歷史(含答題所需事實的「草堆」)載入 Mem0。這包含處理測試資料,結構 mimics LongMemEval——問題連到過去對話 session。
一開始我試一次匯入整個 conversation session。但似乎 suboptimal——Mem0 產生的 distinct memories 比預期少,偵測到的 conversational「events」也較少。雖然沒明寫文件,這暗示一次餵整段 multi-turn dialogue 可能不是 intended 或最有效的方法。
所以我改成 以更小、更 granular 的 chunk 匯入,具體是 user-assistant pairs。 這似乎更符合 Mem0 處理互動的方式。以下是 paired import 策略用的 Python code:
for question in tqdm(data):
for i, messages in enumerate(question['haystack_sessions']):
# Skip if messages is empty or has only one element
if len(messages) <= 1:
try:
client.add(
messages,
user_id=f"longmemeval-test",
metadata={
"question_id": question['question_id'],
"question_date": question['question_date'],
"haystack_date": question['haystack_dates'][i],
"haystack_session_id": question['haystack_session_ids'][i]
}
)
except APIError as e:
print(f"Error adding memory for question {question['question_id']}, session {i}: {e}")
continue
# Break messages into chunks of 2
for j in range(0, len(messages), 2):
chunk = messages[j:j+2]
try:
client.add(
chunk,
user_id=f"longmemeval-test",
metadata={
"question_id": question['question_id'],
"question_date": question['question_date'],
"haystack_date": question['haystack_dates'][i],
"haystack_session_id": question['haystack_session_ids'][i]
}
)
except APIError as e:
print(f"Error adding memory chunk for question {question['question_id']}, session {i}, chunk {j//2}: {e}")
這個 revised 策略——送 user-assistant pairs 附 metadata——感覺是更 robust 的方式,依對話 flow 準確 populate Mem0 的 memory store。
測試 rig:用 GPT-4o 查詢
記憶匯入後,下一步用 benchmark 問題測 retrieval 和 reasoning。如前所述,GPT-4o 當 reasoning engine。以下 Python function 負責從 Mem0 用 client.search() 抓 relevant memories,再組 GPT-4o 的 prompt:
import os
from mem0 import MemoryClient
from openai import OpenAI
client = MemoryClient()
openai_client = OpenAI()
def chat_with_memories(message: str, user_id: str = "default_user") -> str:
# Retrieve relevant memories using Mem0 API
# 👇 CRUCIAL FIX 1: Specify the working output format 'v1.1'
relevant_memories = client.search(
query=message,
user_id=user_id,
limit=3, # Limit the number of retrieved memories
output_format='v1.1'
)
# print(relevant_memories) # Optional: for debugging
# Format the retrieved memories into a string
# Note: Accessing ["results"] key which contains the list of memories in v1.1
memories_str = "\n".join(f"- {entry['memory']}" for entry in relevant_memories.get("results", [])) # Use .get for safety
# Prepare prompts for GPT-4o
system_prompt = f"You are a helpful AI. Answer the question based on query and memories."
# 👇 MODIFICATION: Explicitly label memories and provide context
memory_prompt = "Here's some of the memories that we share that might be relevant to the question (yet they may not be relevant to the question). Even if they're relevant you might still need to piece them together to be able to answer the question:\n" + memories_str
print("System prompt: ", system_prompt)
print("Memories prompt: ", memory_prompt)
print("User prompt: ", message)
# 👇 MODIFICATION: Inject memories as a separate user message before the actual query
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": memory_prompt}, # Memory context provided first
{"role": "user", "content": message} # The actual user question/message
]
# print(messages) # Optional: for debugging
# Call the OpenAI API
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=messages
)
assistant_response = response.choices[0].message.content
# Store the new user message and assistant response back into Mem0
# (Assuming you have a separate step/call for this after getting the response)
# e.g., client.add(data=[{"role": "user", "content": message}, {"role": "assistant", "content": assistant_response}], user_id=user_id)
return assistant_response
這套 querying setup 的 key aspects 仍是:
output_format='v1.1': 正確 parse Mem0 search response 的關鍵。- Memories 分開注入: 記憶放在獨立 user message 有助 GPT-4o 區分 context。
- GPT-4o 負責推理: Mem0 檢索;GPT-4o 解讀並作答。
走過 open-source 難關、選定 commercial API、實作 paired-message import、架好這套 GPT-4o 整合之後——Mem0 在我們 5 題 IE 和 MR 上表現如何?終於看結果。
令人意外的結果:Mem0 為什麼絆倒
架好 benchmark、調整 import 策略、用 Mem0 commercial API + GPT-4o 跑完測試之後……結果老實說 爛到出乎意料。
Mem0 沒能正確回答 targeted Information Extraction (IE) 和 Multi-hop Reasoning (MR) 的全部 5 題。
一開始我懷疑 retrieval 問題。會不會 Mem0 只是沒 surface 對的 memories?但挖深發現更 fundamental 的問題:相關資訊常常根本沒被 capture 成可搜尋的「memory」。
關鍵:摘要把細節洗掉了
重點在這,直接連到 Mem0 內部怎麼 work(概念上見他們架構圖):
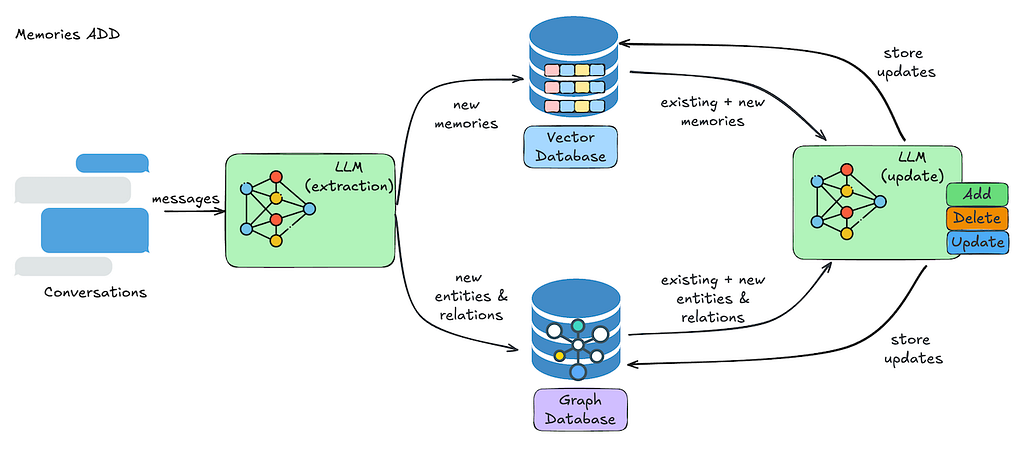
- LLM Summarization: 你 add 對話歷史時,Mem0 不是只存 raw text 供日後搜尋。它先把 messages 過一層 LLM。這個 LLM extract 關鍵資訊、summarize 互動,conceptualize 成 Mem0 定義的「memory」。(見圖:messages 進「LLM (extraction)」block)
- Indexing the Summary: 這個 summarized memory(以及為 graph database 抽的 entities/relations)才會被 embed、index 進 vector database 和 graph database。
- Original Text Sidelined: 原始對話 messages 確實存在某處(UI screenshot 可看到 raw text 連到 summarized「Memory」),但似乎不是 search function 的主要目標。 search 運作在summarized、conceptualized memories 上。
這步 summarization 就是 precise detail retrieval 會崩的地方。LLM 可能從詳細 exchange 做出高層 summary 如 「User is worried about the medical examination part of the green card application process.」,但 lose 之後答 pointed questions 需要的 specific nuances 或 exact phrasing。
具體失敗案例:
benchmark 兩個例子完美 highlight 這點:
Spotify 播放清單(簡單 IE — User):
- Question: 「What is the name of the playlist I created on Spotify?」
- Context: 使用者先前說:「…I've been listening to this one playlist on Spotify that I created, called Summer Vibes, and it's got all these chill tracks…」
- Expected Answer: 「Summer Vibes」
- Result: Mem0 失敗。為什麼?LLM 可能 summarize 這段時 focus 在使用者對音樂 streaming 或 genre(ambient/lo-fi)的興趣, deem 特定 playlist 名稱是 minor detail,不值得放進它建立並 index 的核心「memory」。若 searchable summary 裡沒有「Spotify」或「playlist」,Mem0 就檢索不到,即使 raw text 某處存在。關鍵 summarization/indexing 步驟就被 overlook 了。
西洋棋著法(較難 IE — User):
- Question: 「I'm looking back at our previous chess game and I was wondering, what was the move you made after 27. Kg2 Bd5+?」
- Context: 對話討論特定棋局序列(如「27. Kg2 Bd5+ 28. f3 …」)但沒明確用「chess」這個字。
- Expected Answer: 「27. Kg2 Bd5+」之後的特定著法(例如「28. f3」)。
- Result: Mem0 失敗。又是 summarization 的鍋。沒有「chess」關鍵字,LLM 可能做出 vague memory 如 「User and Assistant discussed moves in a board game.」 具體代數記譜(Kg2、Bd5+)幾乎不可能進那個高層 summary。答題需要的 crucial detail 從未被 index 成可搜尋格式。
Takeaway:
Mem0 用 LLM 預處理、把對話 summarize 成 abstract「memories」再 index 的做法,對需要 precise recall 的任務 fundamentally flawed。只靠這些 summaries 做 retrieval,會 lose 很多實務 use case 裡真正算「記憶」的細節。不是 Mem0 找不到針;是它從一開始就沒把針放進可搜尋的草堆。
結論:尋找真正 AI 記憶的路還很長(Nekobun 需要它!)

那 Mem0 的 verdict?至少對我來說,暫時 pass。
我挖 AI 記憶框架的動機,來自做 Nekobun(https://launch.nekobun.app/)這個 AI 電子書閱讀器。夢想是可愛貓角色不只評論文字,還能跟使用者 genuinely insightful 對話——記得過去討論、偏好、共同時刻,打造真正個人化體驗。那種個人化完全仰賴 robust、可靠的記憶系統。
可惜這次 Mem0 實驗 highlight 一大 hurdle。概念吸引人,但依賴 LLM-based summarization 在 index 之前,對 recall 特定細節是 fatal。對話裡提到的關鍵事實——像 playlist 名稱或特定棋步——在 summarization 過程就 vanished,從未進 searchable memory store。細節沒被 index,就無法 recall,不管 retrieval 演算法或 downstream LLM 多強。
這讓我 wonder:缺乏 production-ready、保留細節的記憶,會不會是我們還沒看到真正 groundbreaking、深度個人化 B2C AI 應用爆發的 key reason?我們有 GPT-4o 這種超強 LLM,如果給對資訊就能 amazing reasoning。但設計來在長互動中持續餵資訊的系統似乎 lagging。「記憶」這塊感覺像 critical missing piece。
LLM 無可否認很聰明,但要達到我們直覺上對「記憶」期待的 persistent、detailed recall,比 hype 暗示的難。它們還沒夠聰明(或至少夠 reliably recall-capable)…… yet。
所以 search 必須繼續。Mem0 只是第一個我丟進 LongMemEval-inspired 顯微鏡的框架。接下來會測其他熱門方案——open-source 和 commercial——看有沒有人能在不犧牲細節的前提下 handle 真正長期 recall 的 nuanced 需求。
你有特別好奇、或覺得可能 crack 這顆堅果的記憶框架嗎?留言跟我說!很想聽你下一輪測試的建議。
如果你喜歡這篇,想多看 AI、技術,或我 AI 電子書閱讀器Nekobun的更新,歡迎在 X 追蹤@CalvinJianbaiKU。很想跟你交流想法!
原文發表於 Medium。